
Analyst(s): Brendan Burke
Publication Date: March 18, 2026
NVIDIA GTC 2026 Day 1 centered on the company’s evolution into a foundational provider of planetary-scale infrastructure, driven by the Vera Rubin platform and the new “AI factory” model for industrializing the AI token economy. This shift signifies the “inference inflection” point, marked by a portfolio approach to Agentic AI with workload disaggregation, a massive $27 billion infrastructure deal between Nebius Group and Meta, and key product announcements from partners like Micron and HPE.
What is Covered in This Article:
- AI factories as the new data center model
- Disaggregated compute in the Vera Rubin platform
- NVIDIA’s expansion into seven chips and five racks
- Physical AI moving toward industrial scale
- Agentic workflows transforming engineering design
The Event — Major Themes & Vendor Moves: NVIDIA GTC 2026, held at the San Jose Convention Center with over 20,000 in-person attendees, officially signaled the industrialization of the AI token economy. The central thesis presented during Day 1 is NVIDIA’s complete metamorphosis from a fabless semiconductor designer into a foundational provider of planetary-scale infrastructure. The overarching narrative of the event firmly established the concept of the AI factory, a purpose-built, gigawatt-scale facility with the token as the primary unit of economic output.
Through a comprehensive, multi-year product roadmap spanning from the current Blackwell architecture through the newly unveiled Vera Rubin platform, and pointing toward the future Feynman architecture, NVIDIA is providing the ecosystem with the multi-year planning certainty required for massive capital deployment. The Vera Rubin platform, engineered specifically to address the unprecedented computational demands of Agentic AI, represents an extreme application of full-stack co-design.
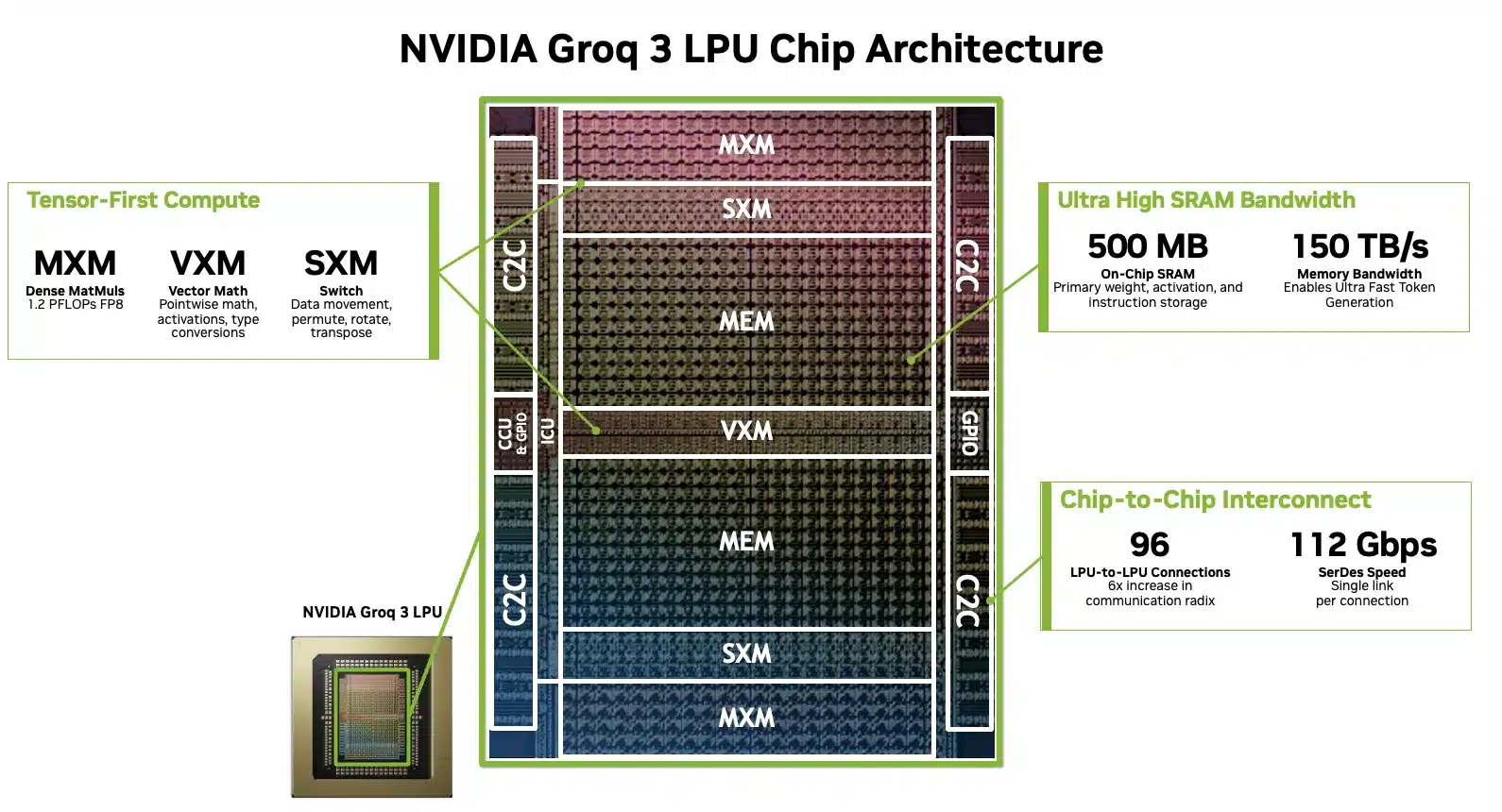
This evolution is driven by the emergence of a fourth scaling law, categorized as agentic scaling, wherein AI systems autonomously reason, utilize external tools, and communicate directly with other AI agents in complex, multi-step workflows. This includes the launch of the third generation of the newly licensed Groq Language Processing Unit (LPU) technology to resolve the inherent dichotomy between high-throughput batch processing and ultra-low-latency interactive inference.
The event provides a stage for NVIDIA’s ecosystem to align with the AI Factory vision. The most staggering market signal was Nebius Group’s $27 billion infrastructure deal with Meta, which includes $12 billion in dedicated Vera Rubin capacity. To feed these systems, Micron announced high-volume production of HBM4 36GB memory, allaying concerns of production delays and delivering a 2.3x bandwidth improvement over previous generations. Serving the role of Groq in Physical AI, NXP Semiconductors announced a foundational partnership with NVIDIA to address deterministic reliability in Physical AI, integrating the NVIDIA Holoscan Sensor Bridge with NXP’s highly integrated edge processor.
Meanwhile, HPE, NeuReality, and Synopsys are moving up the stack. HPE is integrating Blackwell GPUs into its Private Cloud AI with enhanced agentic security, NeuReality launched NR-Nexus to orchestrate rapidly diverging inference workloads across heterogeneous hardware, and Synopsys is leveraging the NVIDIA Agent Toolkit to revolutionize electronic design automation (EDA) through autonomous agent workflows.
NVIDIA GTC 2026 Day 1 – Can NVIDIA’s Ecosystem Accelerate the Inference Inflection?
Analyst Take — The Portfolio Approach to Agentic Scaling: The central thesis of GTC 2026 is that we have crossed the “inference inflection” point. The core of this transformation is the NVIDIA Vera Rubin platform, which disaggregates traditional compute into specialized, rack-scale systems. Key moves included the introduction of the Vera CPU, designed for the sequential reasoning required by agentic AI, and the announcement of third-generation Groq Language Processing Units (LPUs) for deterministic, low-latency token generation in the decode phase of the inference lifecycle. To support backward compatibility and future expansion, NVIDIA announced the Oberon system for copper scale-up and the vertical Kyber rack, which utilizes a new backplane to expand the NVLink domain to 144 GPUs, with optical scale-up reaching 576 GPUs in a unified domain. NVIDIA emphasized its horizontally open approach to emerging technologies like silicon photonics, not ruling out any emerging components.
The shift toward agentic AI and reinforcement learning (RL) has fundamentally redefined the role of the CPU, transforming it from a mere system coordinator into a critical compute engine for low-latency reasoning and orchestration. As highlighted by NVIDIA’s introduction of the Vera CPU and Intel’s Xeon 6 integration into DGX Rubin systems, dedicated high-performance CPUs are now essential to manage the intensive data preprocessing and environment simulations required for RL without bottlenecking the GPU. Vera allows NVIDIA to capture market share in a standalone CPU business that is already generating billions of dollars in revenue. CoreWeave expects to be among the first cloud providers to deploy the NVIDIA Vera CPU rack in production in the second half of 2026, aligning with their software support for RL efficiency.
Similarly, the Bluefield-4 STX reference architecture moves NVIDIA into the AI-native storage market, addressing the high-responsiveness demands of agents that must manage massive key-value cache data. NVIDIA captures share in this sector by providing these modular designs to the entire storage ecosystem, ensuring its silicon sits at the heart of third-party storage solutions. Meanwhile, Spectrum-6 networking expands NVIDIA’s influence into the broader data center fabric market. Collectively, these strategic additions support a projected revenue outlook of at least $1 trillion through 2027 as the industry shifts from traditional software models to “agent-as-a-service.”

Workload Disaggregation Pushes AI Beyond the GPU
Jensen Huang validated that achieving fast AI at high throughput requires rearchitecting and disaggregating inference workloads. He acknowledged that Nvidia’s Vera Rubin GPUs are perfectly suited for the prefill stage of inference, which he described as the easier part, while offloading the bandwidth-limited decode workload to Groq LPUs. To support this, Huang confirmed that Samsung is manufacturing the Groq LPU chips for Nvidia. He suggested this LPU integration is best utilized for high-value engineering and coding tokens that demand extreme low latency, recommending that data centers allocate roughly 25% of their total compute to this Groq-enhanced setup and leave the remaining 75% as entirely Vera Rubin GPU infrastructure.
However, this strategy faces a direct challenge from Cerebras, which recently announced a major partnership with AWS to achieve significant efficiencies in decode paired with AWS Trainium. While Nvidia positions its fastest Groq-enhanced latency tier as a smaller subset of data center compute, Cerebras’s Andrew Feldman noted that the market share for fast inference will not stop at 25%, but will rapidly scale to 60% or 80%. To counter these challenges, Nvidia is relying on extreme co-design and vertical integration, driving the Groq design and new software operating systems like Dynamo into their future AI factories to capture both high-throughput and low-latency market segments.
Demonstrating ecosystem support for the workload disaggregation at the core of the Groq strategy, networking silicon disruptor NeuReality’s NR-NEXUS inference operating system was announced as a critical piece of the puzzle. By disaggregating prefill and decode tasks across heterogeneous hardware including GPUS, CPUs, and NICs, NR-NEXUS transforms fragmented GPU clusters into high-efficiency token factories, maximizing the ROI of expensive Vera Rubin deployments.
Chip Design Expands to the Physical World
At NVIDIA GTC 2026, the competitive landscape of Electronic Design Automation (EDA) expanded as Cadence and Synopsys unveiled significant advancements in agentic AI and GPU-accelerated engineering infrastructure. Cadence expanded its collaboration with NVIDIA by introducing the ChipStack AI Super Agent and a greatly expanded set of physics-grounded solvers for chips and life sciences, all running on the Millennium M2000 Supercomputer built on NVIDIA Grace and Blackwell. Furthering its infrastructure role, Cadence is a key contributor to the NVIDIA Vera Rubin DSX AI Factory reference design, which utilizes the Cadence Reality Digital Twin Platform to help teams design and operate AI factories using physics-based models.
Meanwhile, Synopsys showcased its AgentEngineer technology, which features an industry-first L4 agentic workflow for design and verification, as well as the Synopsys QuantumATK integration with NVIDIA cuEST for accelerated quantum chemistry simulations. Both companies are leveraging the NVIDIA Agent Toolkit and Nemotron models to turn previously impractical simulations, such as Honda’s high-fidelity CFD of its turbofan engine and Micron’s HBM memory design, into routine, automated engineering workflows.
Supply and Demand Strength on Display: HPE, Micron, and Nebius
The most significant demand signal of Day 1 was the massive capital commitment from leading AI cloud providers. Nebius Group announced a landmark five-year, $27 billion AI infrastructure agreement with Meta. This contract includes $12 billion in dedicated capacity powered by one of the first large-scale deployments of the NVIDIA Vera Rubin platform, with delivery commencing in early 2027. Furthermore, Meta has committed to an additional $15 billion in compute capacity across future Nebius clusters over the five-year period.
For AI to move from hyperscalers to enterprise and sovereign deployments, security and workflow integration are paramount. HPE addressed this by offering air-gapped Private Cloud AI configurations for sovereign AI, protected by CrowdStrike and Fortanix. HPE’s solutions now feature network expansion racks capable of scaling deployments up to 128 GPUs, while also offering fully isolated, air-gapped configurations for sovereign AI deployments. To address the unique vulnerabilities of agentic systems, HPE integrated agentic security via CrowdStrike for Al-powered threat detection, and certified its ProLiant DL380a Gen12 servers for Fortanix Confidential AI to ensure sensitive data processing remains unexposed.
On the supply side, Micron announced it has achieved high-volume production of HBM4 36GB 12H memory specifically designed for the NVIDIA Vera Rubin platform. This memory delivers over 2.8 TB/s of bandwidth, representing a 2.3x improvement over the previous HBM3E generation, alongside a 20% increase in power efficiency. Micron is also sampling HBM4 48GB 16H stacks to further push capacity limits.
To address the data path bottleneck in agentic AI, Micron unveiled the industry’s first PCIe Gen6 data center SSD, the 9650, which is currently in high-volume production and optimized for the NVIDIA BlueField-4 STX architecture. Delivering up to 28 GB/s of sequential read throughput and 5.5 million random read IOPS, it doubles the read performance of Gen5 drives, eliminating data-path bottlenecks inherent in large-scale agentic reasoning.
Physical AI Finding Its Legs: CoreWeave, Nebius, and NXP
Recent announcements in physical AI mark a significant shift toward industrial maturation, emphasizing high-performance data center design, robotics cost savings, and efficiency. Nebius has integrated the NVIDIA Physical AI Data Factory Blueprint into its global infrastructure to solve the three-computer problem of unifying large-scale GPU training, simulation, and edge deployment. This purpose-built cloud environment utilizes NVIDIA RTX PRO 6000 Blackwell Server Edition GPUs and NVIDIA OSMO agentic orchestration to provide a managed service that eliminates the need for teams to provision their own clusters or manage complex integrations. Physical AI requires customized cloud computing architectures that not all cloud operators have prioritized.
Software maturation is further highlighted by the collaboration between CoreWeave’s Weights & Biases and NVIDIA, which introduced new blueprints for training Reinforcement Learning (RL) and Vision-Language-Action (VLA) models, alongside tools to track multimodal experiments and compare simulation outputs side-by-side. These software advancements, combined with NVIDIA Cosmos foundation models, have allowed early developers like RoboForce to reduce pipeline setup times by over 70% and cut development iteration cycles from weeks to days.
On the hardware side, integrating the NVIDIA Holoscan Sensor Bridge with NXP’s highly integrated SoCs represents a major leap in cost efficiency and design. This synergy reduces the number of discrete components required for robotic sensing and actuation, which significantly shrinks the physical footprint, power consumption, and overall system cost. Furthermore, this integration establishes a direct transport route between the robot’s body and brain, substantially reducing latency and simplifying the software complexity required for real-time, reliable data processing. There was a high volume of robotics model releases and recent impressive partnerships with leaders like ABB, yet extreme co-design will need to come to robotics hardware engineering to lower costs.
Accounting for the Complexity of Disaggregation
As NVIDIA pushes beyond GPUs into CPUs, networking, storage, and disaggregated inference systems, it faces the risk of diluted engineering focus and rising validation complexity, which can lead to inconsistent performance and harder-to-manage deployments rather than outright chip defects. The challenge is that more tightly coupled components increase the burden on software tuning and system integration, raising the chance of uneven outcomes across customers.
NVIDIA can mitigate this by consolidating complexity into its software stack, centered on CUDA, while also providing tightly defined reference architectures for AI data centers that standardize how its components are deployed together, reducing integration risk and shortening time to production. By pairing these reference designs with strong ecosystem incentives to adopt its frameworks and proprietary models, NVIDIA can align hardware, software, and infrastructure around a consistent blueprint and maintain system-level coherence as its portfolio expands.
What to Watch:
- The HBM4 Supply Chain: Watch for whether Micron and other memory makers can scale HBM4 production fast enough to meet the 2027 delivery targets.
- Groq-NVIDIA Synergy: Monitor demand for high-interactivity AI inference to evaluate the likely contribution of the Groq 3 LPX Rack as it scales in volume production over the next two years.
- Sovereign AI Adoption: Watch HPE’s progress in government and regulated sectors; their air-gapped configurations could be the catalyst for the next wave of non-hyperscaler CapEx.
- Inference Market Share Dynamics: Monitor the competitive split between NVIDIA’s 25% Groq-enhanced latency tier and rival architectures (like Cerebras/AWS), to see if fast inference market share scales toward Cerebras’ projected 60% to 80% mark.
- Software Resilience of the AI Factory: Observe whether NVIDIA can successfully mitigate the validation complexity introduced by its vertically integrated stack through its reliance on agentic chip design and the Nemotron Coalition.
You can read more about announcements at NVIDIA GTC on the company’s website.
Disclosure: Futurum is a research and advisory firm that engages or has engaged in research, analysis, and advisory services with many technology companies, including those mentioned in this article. The author does not hold any equity positions with any company mentioned in this article.
Analysis and opinions expressed herein are specific to the analyst individually and data and other information that might have been provided for validation, not those of Futurum as a whole.
Other Insights from Futurum:
At GTC 2026, NVIDIA Stakes Its Claim on Autonomous Agent Infrastructure
Can Applied Materials and Micron Crack the Materials Barrier Holding Back HBM?
NVIDIA and CoreWeave Team to Break Through Data Center Real Estate Bottlenecks
Image Credit: Gemini
Author Information

Brendan is Research Director, Semiconductors, Supply Chain, and Emerging Tech. He advises clients on strategic initiatives and leads the Futurum Semiconductors Practice. He is an experienced tech industry analyst who has guided tech leaders in identifying market opportunities spanning edge processors, generative AI applications, and hyperscale data centers.
Before joining Futurum, Brendan consulted with global AI leaders and served as a Senior Analyst in Emerging Technology Research at PitchBook. At PitchBook, he developed market intelligence tools for AI, highlighted by one of the industry’s most comprehensive AI semiconductor market landscapes encompassing both public and private companies. He has advised Fortune 100 tech giants, growth-stage innovators, global investors, and leading market research firms. Before PitchBook, he led research teams in tech investment banking and market research.
Brendan is based in Seattle, Washington. He has a Bachelor of Arts Degree from Amherst College.





