
Analyst(s): Olivier Blanchard, Brendan Burke
Publication Date: June 12, 2026
Document #: AIOOBBB202605
Desktop AI Hubs Could Be the Answer to Not Only Our AI-related Power Grid Infrastructure Challenges but Scalable Robotics Deployments As Well
Key Points
- NVIDIA’s DGX Spark could serve as the template for a new category of devices serving as home AI hubs capable of handling concurrent inference for 10–15 active devices locally.
Next-generation wireless standards (Wi-Fi 8 and 6G) enable a “Local Mesh Orchestrator” model that could reduce cloud dependency for AI inference, optimize battery life for edge peripherals, and enable greater penetration of thin-client AI devices. - An 86-million-home install base for AI hubs represents a massive, untapped computational infrastructure capable of smoothly operating within the 180 GW safety envelope of the existing US residential grid.
- The decentralized nature of the network, operating within the existing 180 GW residential envelope, allows it to act as a critical stabilizer for the soon-to-be overstretched US power grid by managing peak power demands without requiring industrial generation expansion or overtaxing localized neighborhood power infrastructure.
- By intercepting and distributing just 8 hours of daily inference workloads across 86 million desktop units, such a decentralized edge network could successfully deflect 56.23 TWh of raw computing load away from the core annually.
- AI hubs could also serve as key enablers of consumer robotics by offloading Vision-Language-Action (VLA) models to solve Battery and Thermal walls, and securely running reinforcement learning simulations on a home’s digital twin to save on token costs and ensure additional layers of privacy.
Recommendations for Vendors in the AI Platform and AI Hardware Space
- Begin Establishing the Home AI Hub’s Reference Architecture as a Local AI Training and Inference Anchor Device: Develop and champion a specialized residential AI hub product line (based on the GB10 DGX Spark or equivalent platform) that focuses on high performance-per-watt sustained local inference. The architecture must integrate next-generation connectivity (Wi-Fi 7/8 and 6G) to also function as a local mesh orchestrator for AI-enabled devices, and provide seamless edge-to-cloud simplicity, allowing developers and users to deploy models instantly with zero code changes.
- Capitalize on Token Anxiety: Shift the consumer value proposition from raw performance to long-term economic utility and data security. Market the AI hub as a fixed CapEx investment and unmetered intelligence solution that prevents users from falling into the cloud’s escalating pay-per-token OpEx trap. Also emphasize its ability to alleviate future token anxiety for AI prosumers.
- Engage Utility Providers and Service Partners to Establish Leasing Models and Demand Response Programs: Leverage the hub’s power characteristics to act as a Grid Stabilization tool, tap into the nation’s 180 GW residential electrical reservoir, and provide households with an opportunity to sell AI compute to third parties.
- Align Future R&D to Enable Thin-Client Robotics: Future platform roadmaps should be aggressively aligned with the precise, low-latency requirements of the post-2028 consumer robotics market. The primary goal there will be to solve the so-called battery and thermal wall by engineering architectures capable of offloading VLA models from the robot to the hub and reducing the robot’s onboard compute draw from 150W to as low as 10W. This centralized hub-based processing and continuous local simulation could be the missing link for making consumer robotics viable at scale.
What You Need To Know
Making the Case for the Home AI Hub
The next major hardware frontier for chipmakers and device OEMs could be the Home AI Hub (or “Compute Router”). This category of device would help shift the AI compute paradigm from today’s binary of cloud-based inference coupled with individual devices carrying battery-draining AI chips to a more federated, more efficiently orchestrated edge-enabled model. This model would hinge on the deployment of small, high-performance local AI inference endpoints that could not only handle a significant portion of a household’s inference workloads without reliance on the cloud, but also serve the compute needs of modern connected households’ entire mesh of devices. And yes, this category of device could also be the key to making consumer robotics scale – a point we will discuss in a moment.
The GB10-Based NVIDIA DGX Spark
While we are still a few years away from the types of specs and performance that an AI hub will eventually need to handle a mature agentic ecosystem for US households, the NVIDIA DGX Spark is a great starting point for this category:
- Performance: Delivers 1,000 TOPS of AI compute, features 128GB of unified VRAM, to support models with up to 200 billion parameters.
- Platform: 128GB of unified LPDDR5X memory. It runs the Linux-based NVIDIA Base OS, ensuring edge-to-cloud simplicity where developers can move workloads between local hubs and DGX Cloud with minimal code changes. This is a significant leadership advantage for NVIDIA right out of the gate.
- Efficiency: Draws roughly 120W (or between 110W and 125W) during active inference compared to 140W+ for competing X86 platforms, and only about 28W when idle.
Connectivity and Device Support
Compute isn’t the only factor to consider here. An AI Hub must also leverage a sophisticated wireless fabric in order to function as a Local AI Mesh Orchestrator:
- Wi-Fi 7: Uses Multi-Link Operation (MLO) and 320 MHz channels to provide a bandwidth firehose, matching the feel of a wired PCIe connection for high-resolution image or PDF transfers.
- Wi-Fi 8: Introduces “Deterministic Latency” (<1 ms jitter), critical for real-time AI agents and voice assistants to ensure fluid, synchronized feedback to multiple wearables simultaneously.
- 6G & ICC: Through Integrated Communication and Computing (ICC), the hub extends its reach beyond the home, allowing mobile devices to route queries back to the residential hub via ultra-low-latency carrier slices.
- Concurrent Capacity: A single hub comfortably supports 10 to 15 devices simultaneously for heavy interactive tasks (e.g., LLM coding, XR overlays) or up to 100+ low-frequency IoT endpoints such as smart sensors.
Current Barriers to Adoption in the Home
The strong demand and repeated sellouts of the Apple Mac Mini suggest that AI prosumers are becoming a real and growing hardware market, with users increasingly buying systems specifically for local AI inference, agent workflows, and private always-on compute rather than traditional desktop tasks alone. The Mac mini’s combination of high unified memory (UMA), strong inference efficiency (shoutout to the MLX framework), quiet operation, and relatively low cost made it one of the first consumer-friendly devices capable of acting like a compact personal AI server, lowering the barrier for developers, creators, and power users to run local models continuously.
At the same time, its success may say less about tiny desktops being the permanent form factor and more about rising demand for persistent local AI infrastructure in general. Over the long term, consumer AI will likely evolve into a hybrid architecture where lightweight AI runs across phones and laptops while dedicated home compute nodes handle memory, orchestration, privacy-sensitive tasks, and persistent agents – making the Mac mini potentially an early indicator of a broader shift toward personal AI infrastructure rather than the final end-state device itself.
The most obvious question for the growth potential of this niche, however, is always the same: Why would the mass market want AI infrastructure? As with all new technologies that aren’t immediately seen as a necessity, convincing consumers to invest in home server racks will take some work.
Currently, the category would face additional barriers to mass adoption: In addition to the high price point, the consumer-facing agentic ecosystem isn’t anywhere close to being mature enough to require an AI hub to begin with, at least at scale. Connected devices in the home aren’t yet designed to sync with an AI hub. As for robots and other AI-powered appliances in the home, most remain too unsophisticated to require an AI hub. And lastly, data centers can still handle compute capacity for most of the US market’s inference demand.
In other words, it is too soon for home AI hubs to enter the market, but this will change over the course of the next few years. The introduction of this category of device (along with the software and services ecosystem around it) around the 2028–2030 timeframe will be necessary to help not only address the next decade’s need for more inference capacity and the power grid challenges that come with it, but also to help both optimize and scale AI inference at the edge in a way that makes both economic and engineering sense: As inference demand begins to outstrip supply, cloud-centric token economics begin to stress budgets, and intelligent devices in the home (including robots) enter the mainstream, AI hubs will move from the conceptual stage to a market necessity. So long as price points can be adjusted downward, or these devices can be leased or rented through a utility or subscription service, the price objection can be mitigated.
Key Benefits of Home AI
As consumers increasingly rely on AI in their personal and professional endeavors, the economics of home AI infrastructure should be financially justifiable. For an AI software developer, the $4,500 DGX Spark can pay for itself in about a month, per Signal65’s The NVIDIA DGX Spark Platform: Arm and NVIDIA Reinvent the Workstation report. (This calculation is based on an H100 instance capable of running 120B-parameter models at comparable inference throughput, costing approximately $6.00 per hour at current cloud market rates.) For consumers, however, utilization rates will likely be far lower, even in a more mature agentic and physical AI environment. This will naturally stretch the breakeven point much further, but positive ROI can still be achieved as users grow increasingly dependent on AI workloads, and as having their own token factory begins to address critical concerns that cloud providers may not be able to handle.
For consumers, the most significant benefits of adding an AI hub to their home, once inference demand and tokenomics warrant the product category’s introduction to the market, are fairly obvious:
- Data Privacy & Security: Sensitive data (such as calendars, queries, agentic workloads, audio and video data, and user preferences) can remain within the walls of the home, bypassing the need to send private or otherwise personal information to cloud data centers and making it accessible to data brokers.
- Latency Improvements: Sub-10ms response times for voice and spatial AI, which is impossible with cloud round-trips exceeding 100ms. This is especially important as natural language interfaces become more prevalent in agentic UX.
- Unmetered Intelligence, Cost Arbitrage, and The New Tokenomics: By processing a large portion of household AI workloads locally, users will be able to avoid the pay-per-token trap of cloud APIs. Note that token pricing is almost certain to rise as demand increasingly outstrips supply. Shifting to local compute transforms AI from a variable OpEx (per-token API fees) to a fixed CapEx (hardware investment), and helps alleviate future token anxiety. A heavy-use household could reasonably save $400–$1,000 per year by installing its own token machine inside the home.
- “Thinner” Client AI Device Enablement: Having an AI compute hub in the home also allows for more thin-client AI-capable devices that could, over time, allow households to spend less on high-performance hardware since much of the inference workloads they would normally have to handle on their own can be outsourced to the hub. This will be particularly relevant as AI-enabled home appliances, including robots, become more mainstream.
Essentially, the home AI hub will transform from what is now a premium professional workstation into a managed utility – a sort of compute router – that will backfill AI compute for AI-enabled connected households, power the next generation of autonomous physical AI, and could even help address critical AI infrastructure bottlenecks.
Mitigating AI Infrastructure Constraints: Operating Within the 180 GW Envelope
One of the more intriguing and valuable aspects of the Home AI Hub category is the structural relief it brings to centralized AI infrastructure bottlenecks. Rather than demanding concentrated, slow-to-build industrial grid expansions, this model shifts execution to the edge.
The structural footprint of this network is massive. Approximately 86 million single-family households represent a collective baseline electrical grid envelope of around 180 GW. Based on data from the U.S. Energy Information Administration (EIA), the total U.S. residential electricity consumption runs over 1.5 trillion kilowatt-hours annually – a volume that, annualized, translates to an average continuous power draw of roughly 180 GW. By deploying local hubs operating at an active 140W system-on-chip baseline, the entire 86-million-home network draws a concurrent peak load of 12.04 GW. This means the entire decentralized computing grid utilizes less than 6.9% of the existing residential electrical footprint, seamlessly absorbing massive computational workloads within the infrastructure already embedded in the nation’s walls.
The dominant narrative around AI power demand treats industrial generation and high-voltage transmission buildout as the ultimate binding constraint. But this residential footprint suggests a different question: is the constraint truly raw generation, or is it geographic aggregation? An infrastructure strategy that dynamically distributes inference workloads across an existing 180 GW residential envelope taps into extraordinary latent headroom, comfortably distributing localized thermal and electrical loads without requiring overtaxed commercial substations to scale.
For AI workloads specifically, this framing elevates distributed compute architectures, demand-response orchestration, and off-peak token monetization as highly practical complements to the conventional “build more power plants” playbook. The regional electrical distribution infrastructure is already built; a federated network of intelligent edge routers is simply the missing link required to utilize it at scale.
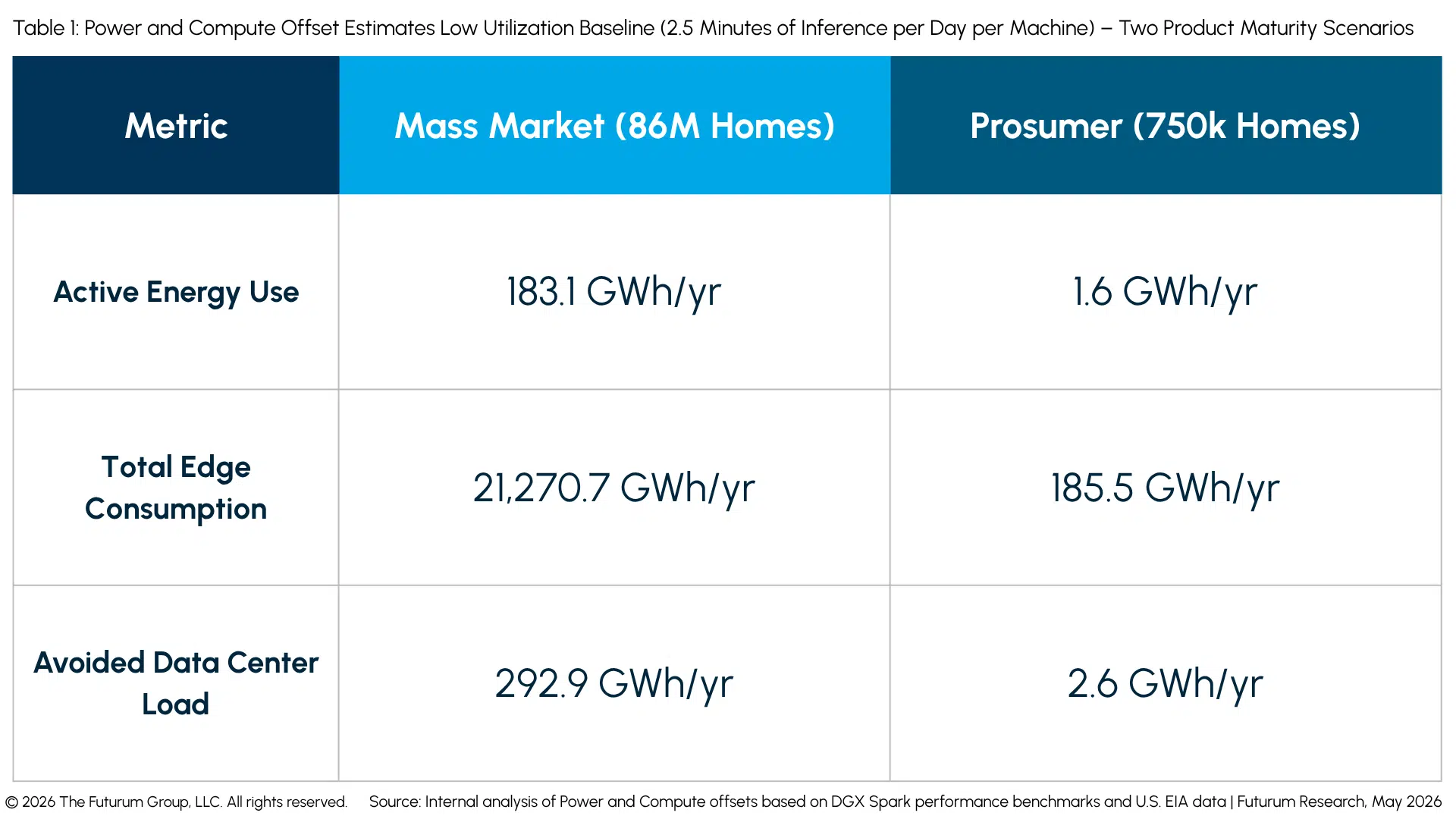
Data Center Offset Analysis: Low Utilization Baseline
Shifting inference to the residential edge provides a massive relief valve for an overstretched industrial power grid. In an initial mass-market deployment scenario (86 million homes), the baseline consumer footprint is inherently bursty. Unlike a corporate server that processes thousands of data requests every single second, a typical household interacts with its local AI device sporadically. If an average user triggers their AI Hub 15 times a day for smart home commands, agentic tasks, or local coding assistance, each interaction requires only a few seconds of peak execution.
This efficiency is driven by the underlying hardware architecture. Benchmarks show that when running highly optimized, quantized 20-billion to 70-billion-parameter models, the NVIDIA DGX Spark can process prompts at a staggering 3,600 tokens per second and generate responses at roughly 59 tokens per second (utilizing MXFP4 precision). While the hardware can inference models up to 200 billion parameters, its 128 GB of unified LPDDR5x memory and 273 GB/s bandwidth natively favor these slightly smaller, highly efficient models for optimal token generation speeds.
Because an intensive user request – such as instructing an agent to draft an executive brief, analyze a document, or execute a smart home routine – generates roughly 400 to 500 tokens, the GB10 Grace Blackwell Superchip completes the entire reasoning task in under 8 seconds of active computing. While this intermittent consumer baseline represents an incredibly light footprint on the grid, it lays the infrastructure foundation for much higher-yielding, sustained utilization models.
In other words, under this initial low-utilization baseline (Scenario 1: Low Utilization Baseline), the local AI hub is only active for roughly 2.5 minutes per day. When active, the system draws closer to its 140W SOC Thermal Design Power (TDP), or up to 200W+ under maximum system load, rather than a flat 120W average. For the remaining 23 hours and 57 minutes, the device sits in an idle, low-power state pulling a steady 28W.
Even at this minimal consumer footprint, rolling this network up to an aggregate 21,270.7 GWh (21.3 TWh) of annual distributed edge consumption would require nearly 90 million units idling simultaneously across the country. To put that massive scale into perspective, 21.2 TWh accounts for just under 0.5% of the total annual U.S. electricity net generation (which recently reached a record high of approximately 4,430 TWh).
- 292.9 GWh Annual Offset: In a maturing mass-market scenario (deployment to 86 million homes), shifting intermittent consumer inference tasks to local hubs effectively relocates 292.9 GWh of raw computational load from concentrated industrial data centers annually. However, because these edge devices sit in an idle state, pulling 28W for nearly 24 hours a day, they establish a baseline physical footprint of 21,270.7 GWh (21.3 TWh) of annual distributed consumption. This results in a net annual energy burden of nearly 21.0 TWh on the broader grid. Although this scenario is not a net energy solution, it establishes a foundation for distributed infrastructure and demonstrates the network’s capacity to manage peak power demands within the existing residential safety envelope.
- Computational PUE Arbitrage: Centralized data centers operate under strict Power Usage Effectiveness overheads (typically a PUE of 1.1 to 1.6), requiring massive infrastructure for active cooling and power distribution. In contrast, residential platforms such as the DGX Spark achieve a local “Computational PUE” of 1.0 by relying entirely on ambient passive dissipation and standard home airflow. This completely bypasses centralized utility overhead, though it effectively shifts 100% of the minor heat dissipation and localized electrical load directly onto the residential consumer’s environment.
- Grid Stabilization: Tapping into this distributed consumer footprint transforms millions of local devices into a massive, flexible computational buffer. Because these units handle bursts of active inference within a 140W to 200W+ system envelope – sitting safely inside the standard 180 GW baseline residential safety capacity – the grid can absorb these fragmented local spikes. By scheduling heavier non-time-sensitive background tasks to run during off-peak hours, this distributed architecture can actively smooth out regional demand curves and help stabilize the broader electrical grid.
Data Center Offset Analysis: The ⅓ Utilization Case
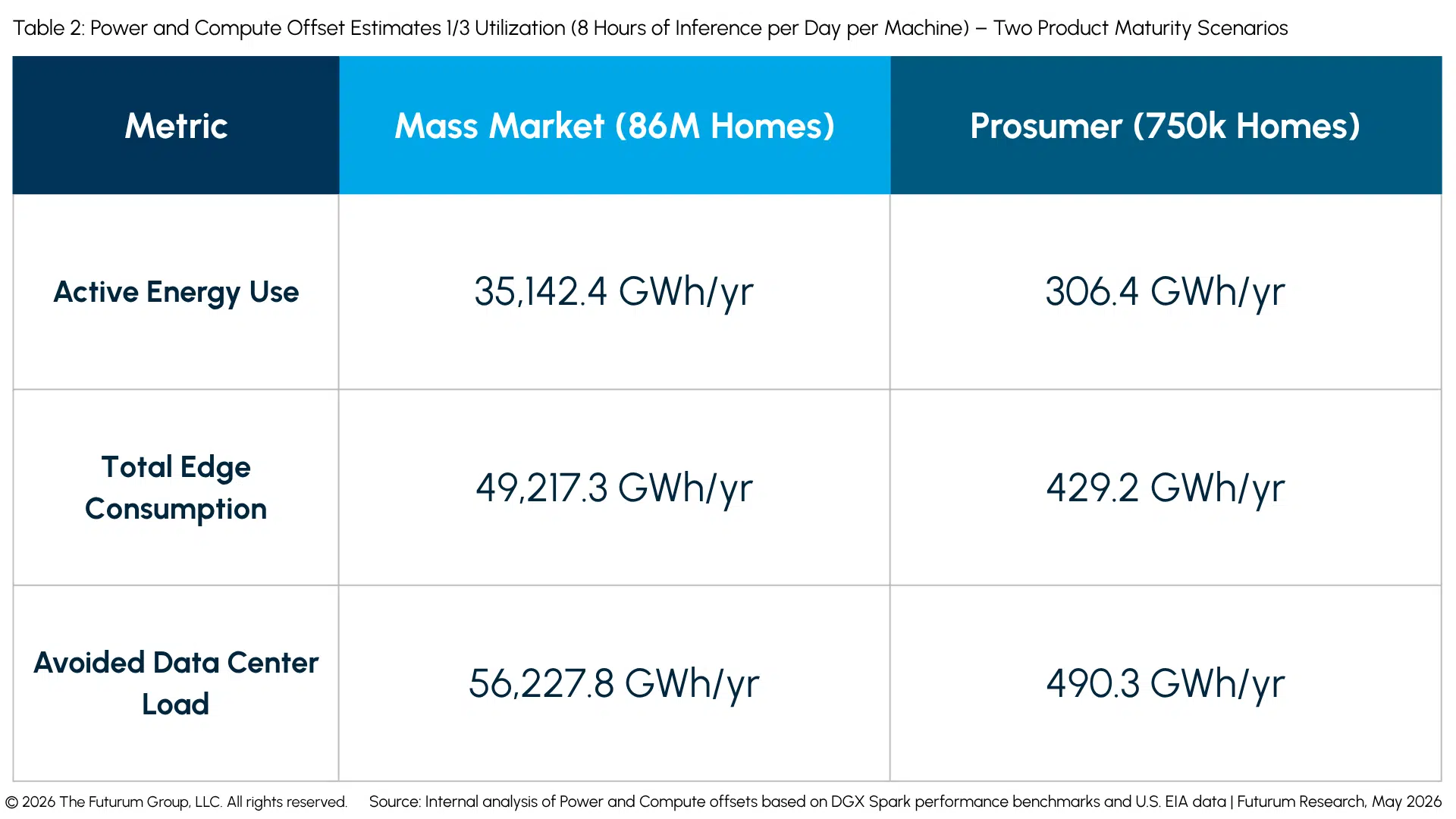
Given that 2.5 minutes of utilization per day leaves these localized assets severely underutilized, consider a scenario where these hubs remain active for an average of 8 hours per day, representing a 1/3 utilization rate over every 24-hour period.
This high-utilization model could be achieved in one of two ways. The first requires an expansion of our install base that includes not only households but small businesses, schools, municipal offices, and local labs where the AI hub handles heavy, professional-grade AI workloads. This would also eventually include households operating networked robots, a trend explored in the Beyond 2028: The Robotics Missing Link section of this report.
In a second scenario, the household, business, school, or municipal office could monetize its idle computing windows by provisioning its hardware capacity to decentralized AI orchestration networks and token brokers. Much like solar-powered households leverage net metering to sell energy surpluses back to the electrical grid, AI hub owners will be able to participate in distributed cloud networks to earn rewards, directly offsetting their upfront hardware costs and incremental utility bills.
What, then, is the aggregate impact of an 8-hour daily inference cycle across those same 86 million units? The numbers scale into massive industrial infrastructure displacement, saving 56,227.8 GWh (56.23 TWh) of centralized data center load annually. For context, this network could completely sideline roughly 58 hyper-scale (100 MW IT load/~110 MW total grid draw at a 1.1 PUE) AI data centers, or more than 13 massive 500 MW computing campuses, effectively decentralizing the future of AI infrastructure without requiring the slow-to-build, high-voltage industrial transmission lines and dedicated substations typical of centralized computing hubs.
- 56,227.8 GWh (56.2 TWh) Annual Offset: In a mature, high-utilization mass-market scenario (deployment to 86 million homes and small businesses), running local inference for 8 hours a day relocates a massive 56,227.8 GWh (56.2 TWh) of industrial data center energy consumption annually. However, because these edge devices must still sit in their 28W idle state for the remaining 16 hours of the day, the aggregate network’s total edge footprint becomes 49,217.3 GWh (49.2 TWh) of annual distributed consumption – meaning the network actually achieves a net energy offset of ~7.0 TWh compared to what it replaces at the core.
- Mass-Scale PUE Arbitrage: Centralized data centers scaling up to meet 8-hour continuous workloads face compounding thermal inefficiencies and immense cooling infrastructure bills (PUE 1.1–1.6). By distributing this computing block across 86 million homes, the aggregate network achieves a relative local “Computational PUE” of 1.0, relying on ambient household airflow and bypassing industrial utility cooling overhead. While this avoids long-distance transmission line losses, it shifts 100% of the continuous thermal dissipation directly into individual residential environments. (Note that in warm climates and summer months, some ventilation may be required to offset the unit’s heat when active, which changes the PUE equation somewhat.)
- Macro Grid Stabilization: Running 8 hours of daily inference opens up massive opportunities for demand-side grid management. By programmatically scheduling these intensive local compute blocks to run during periods of high regional supply – such as midday solar surpluses or overnight wind generation – the network acts as a 12.04 GW to 17.20 GW virtual load buffer (based on a 140W to 200W+ system draw). This allows it to seamlessly absorb stranded energy within the 180 GW residential grid safety envelope to keep the broader macro grid highly stable.
The Infrastructure Paradox: CapEx Displacement vs. OpEx Grid Demands
By intercepting and distributing 8 hours of daily inference workloads across 86 million desktop units, this decentralized edge network successfully deflects 56.23 TWh of raw computing load away from the core annually. In terms of capital infrastructure (CapEx), this massive displacement effectively sidelines the need to construct roughly 58 hyper-scale AI data centers (or as many as 13 massive 500 MW computing campuses).
However, looking at the macro grid ledger reveals a distinct “efficiency tax” inherent to a decentralized architecture. While optimized centralized data centers can spin down or operate at high utilization efficiency, distributed edge hardware introduces an inescapable aggregate “vampire draw.” Because these 86 million desktop devices must sit plugged in at a steady 28W idle state for the remaining 16 hours of the day, they generate a collective 14.1 TWh background idle footprint. When combined with the active computing phase, the total edge consumption is 49.22 TWh, representing a net offset of 7.0 TWh on the broader electrical grid compared to what was replaced at the core.
Based on current grid data and infrastructure trends, the physical grid could support the additional demand of 49,217.3 GWh/year (49.2 TWh/yr), provided that the workload is actively and dynamically managed. If all 86 million homes were to run their devices blindly at the exact same peak time, the resulting 12.04 GW to 17.20 GW surge would cause severe localized grid strain and heavily tax regional distribution infrastructure. However, if managed dynamically through a virtual load buffer, this network should not pose a threat to the grid.
To put 49.22 TWh/year into perspective, total annual U.S. electricity net generation recently reached a record high of approximately 4,430 TWh. Adding this high-utilization network represents only roughly a 1.1% increase in total national electricity demand. Nationally, while this volume of energy requires meaningful integration, it remains well within the grid’s historical capacity cushions and represents a manageable impact on macro power generation when optimized for off-peak hours.
Moreover, because these local inference machines don’t need to respond to a human in real-time when performing heavy batch tasks (e.g., model fine-tuning, video rendering, or agentic data sorting), those eight active hours could not only be digitally shifted to take place primarily during off-peak hours but also further optimized for energy demand efficiency through the use of batteries and renewable energy sources. (Think about states such as California, Texas, and Arizona for solar surpluses, and others for baseline wind generation when human economic activity is minimal.)
Lastly, during the winter months or in colder latitudes, a home AI hub’s estimated 85W–240W draw can act as a baseline thermal offset, effectively making AI computation a useful source of home heating. In the summer months and in warmer climates, the hub’s low-power state and the use of a dedicated ventilation accessory can help manage the unit’s heat signature without noticeably penalizing the home’s cooling efficiency.
The Takeaway: Deploying desktop AI hubs is fundamentally a strategic trade-off. It does not eliminate macro energy demand; rather, it trades centralized industrial capacity constraints for a distributed operational efficiency tax. The network successfully relieves hyper-scalers from building slow-to-permit, high-voltage industrial substations by elegantly scattering the computing and thermal loads across millions of existing residential electrical envelopes – though the nation’s grid must ultimately generate more aggregate power to sustain it.
AI Hub Evolution Beyond the DGX Spark
Should the category find solid footing, we can safely assume that competitors such as AMD, Intel, Qualcomm, and MediaTek would be likely to enter the market with their own solutions and software ecosystems.
But as the ecosystem matures, the arrival of NVIDIA’s Rubin and Feynman platforms would likely further solidify NVIDIA’s market advantage as the reference platform for this product category. Hardware aside, NVIDIA’s software ecosystem continuity between edge and cloud infrastructure should present a compelling strategic advantage that its competitors would have to overcome.
Beyond 2028: The Robotics Missing Link
As mentioned earlier in this report, the expansion of AI into physical form factors such as advanced robotics and humanoid robots may also benefit from this type of device (and the infrastructure around it) to be deployed at scale in order to be commercially viable:
- “Thinner-Client” Robotics: Offloading Vision-Language-Action (VLA) models to a central hub can help solve the so-called Battery and Thermal Wall. Robots intermittently dropping their onboard compute from 150W to as low as 10W could allow for lighter materials, stronger actuators, longer battery life, and perhaps more importantly, lower price points.
- Continuous Local Simulation: While idle, a residential hub can also run reinforcement learning simulations on a home’s digital twin, securely teaching the robot how to navigate new environments without waking the physical machine and, perhaps most importantly of all, without making private data available to third parties. The ability to train robots locally without having to grant outside developers or third parties access to camera and microphone feeds will be critical to making robots, humanoid or not, palatable to consumers.
Conclusion
Looking toward the 2028–2030 timeframe, the Home AI Hub represents a necessary paradigm shift aimed at transforming AI compute from a mostly cloud-centric model into a far more federated, edge-enabled utility model. For consumers, the hub offers compelling benefits such as much-needed new layers of data privacy protection, improved agentic UX through latency improvements, service continuity during network outages, and cost arbitrage for AI tokens, while also serving as a strategic missing link for scaling thin-client robotics. Furthermore, by smoothly operating within the 180 GW envelope of existing US residential capacity and providing a massive 56,227.8 GWh (56.23 TWh) annual offset to industrial data center loads under standard high-utilization cycles, this category of AI compute device is poised to fundamentally transform how we plan for an efficient AI infrastructure and how we design next-generation, thinner-client robots and decentralized AI devices.
What To Watch
- Competitive Cost Challenges: Monitor how competitors such as AMD might leverage their existing high-volume consumer footprints and new AI-powering platforms to undercut NVIDIA’s premium, full-stack edge-to-cloud ecosystem on cost-per-device connectivity, which could challenge the DGX Spark’s market entry strategy.
- Business Model Disruption: Track the early signs of emergence for subscription or leasing models through utility providers or carriers. These could establish a foundation to turn AI Hub from a high CapEx purchase into a managed utility, which will be critical for mitigating initial price friction and driving mass-market adoption.
- Wireless Fabric Maturation: Watch the commercial rollout and ecosystem integration of next-generation wireless standards (particularly Wi-Fi 8 and 6G) by companies such as Broadcom, Qualcomm, and MediaTek, as these technologies will be essential for the AI Hub to achieve the deterministic, low-latency performance required to function as a “Local Mesh Orchestrator.”
- Grid Stabilization and Computational PUE Arbitrage: Watch for policy and utility programs that incentivize tapping into the residential electrical footprint using AI Hubs, which can shift significant amounts of load away from data centers and leverage the home for natural heat dissipation (to achieve a “Computational PUE” near 1.0). Be especially aware of such efforts evolving into regulatory imperatives in environmentally sensitive markets such as the EU.
- Robotics Adoption: Observe the timeline for the maturation of consumer-facing agentic ecosystems, particularly “Thin-Client Robotics,” as the viability of the AI Hub will depend on the mass-market need to offload VLA models from robots in order to solve the battery and thermal constraints.
Other Insights from Futurum:
MediaTek’s Maturing Edge-to-Cloud AI Strategy Expands Beyond Smartphones
SiTime’s 88% Revenue Surge Signals Precision Timing’s New Strategic Role in AI Infrastructure
Orbital Computing Can Reach $1 Trillion Addressable Market by 2030
Disclaimer: The analysis and numerical models presented in this report, specifically Tables 1 and 2 and the associated energy consumption estimates, use the NVIDIA DGX Spark platform as a foundational reference architecture. The power consumption and performance metrics (e.g., 140W active draw, 28W idle draw, 1.6 PUE offset) are derived from initial or expected benchmarks for this device. These figures are illustrative scenarios intended to demonstrate the scale and potential impact of decentralized edge computing. They are not intended as projections for the final technical specifications or market performance of commercially available Home AI Hubs in the 2028–2030 timeframe, which may feature different form factors, power draws, and operational efficiencies across various vendor ecosystems (AMD, Intel, etc.). The report’s core thesis – that a federated network can provide CapEx displacement, grid stabilization, and net energy benefits under high utilization – remains consistent, regardless of future variances in device specifications.
Disclosure: Futurum is a research and advisory firm that engages or has engaged in research, analysis, and advisory services with many technology companies, including those mentioned in this article. The author does not hold any equity positions with any company mentioned in this article.
Analysis and opinions expressed herein are specific to the analyst individually and data and other information that might have been provided for validation, not those of Futurum as a whole.
Read the full Futurum Group Disclosure.
Author Information

Olivier Blanchard is Research Director, Intelligent Devices. He covers edge semiconductors and intelligent AI-capable devices for Futurum. In addition to having co-authored several books about digital transformation and AI with Futurum Group CEO Daniel Newman, Blanchard brings considerable experience demystifying new and emerging technologies, advising clients on how best to future-proof their organizations, and helping maximize the positive impacts of technology disruption while mitigating their potentially negative effects. Follow his extended analysis on X and LinkedIn.

Brendan is Research Director, Semiconductors, Supply Chain, and Emerging Tech. He advises clients on strategic initiatives and leads the Futurum Semiconductors Practice. He is an experienced tech industry analyst who has guided tech leaders in identifying market opportunities spanning edge processors, generative AI applications, and hyperscale data centers.
Before joining Futurum, Brendan consulted with global AI leaders and served as a Senior Analyst in Emerging Technology Research at PitchBook. At PitchBook, he developed market intelligence tools for AI, highlighted by one of the industry’s most comprehensive AI semiconductor market landscapes encompassing both public and private companies. He has advised Fortune 100 tech giants, growth-stage innovators, global investors, and leading market research firms. Before PitchBook, he led research teams in tech investment banking and market research.
Brendan is based in Seattle, Washington. He has a Bachelor of Arts Degree from Amherst College.






