
Analyst(s): Brendan Burke, Olivier Blanchard
Publication Date: June 29, 2026
What Is Covered in This Article:
- Qualcomm’s June 24 Investor Day sizes a roughly $1 trillion data center TAM, split across a $680 billion accelerator market, a $200 billion CPU market, and a $115 billion custom silicon market by fiscal 2029
- The accelerator market is the prize, as we anticipate AI-first servers to cross 50% of server capital spending by 2029 and approach 75% by 2035
- Qualcomm aims its near-memory HBC accelerators at decode-heavy inference, the volume workload that picks the next compute winner
- Qualcomm’s performance-per-watt lineage reorients to attack the next bottleneck of power efficiency
- Near-memory High Bandwidth Compute presents a technical wedge, AlphaWave SerDes earns the right to win custom silicon, and the C1000 CPU is the unproven leg
- The Modular acquisition hands Qualcomm the heterogeneous scheduling layer for the disaggregated, multi-vendor data center that CUDA was never built to provide
The Event—Qualcomm Stakes Its Data Center Claim on June 24: Qualcomm held its 2026 Investor Day on June 24 at the venue where it laid out a data center strategy it has teased since 2025. The San Diego company built its name in mobile and withdrew from servers in 2018, so this was a reentry rather than a debut. The event followed three moves that gave the strategy substance:
- At Computex 2026, Qualcomm introduced Dragonfly as its data center brand.
- In December, it closed the 2.4 billion dollar Alphawave Semi acquisition a quarter ahead of schedule and put Alphawave founder Tony Pialis in charge of the data center business.
- Days earlier, it acquired RISC-V CPU designer Ventana Micro Systems.
On June 24, Qualcomm detailed a full data center portfolio under the Dragonfly brand, organized around four product lines that ramp in sequence: connectivity in fiscal 2026, custom silicon from the first quarter of fiscal 2027, the AI accelerator in the second half of fiscal 2027, and the CPU in the second half of fiscal 2028.
The C1000 is a CPU fleet built on Qualcomm Oryon cores with more than 250 cores per device, in three configurations: an agentic CPU, a general-purpose CPU for virtualized container workloads, and an AI head node CPU that orchestrates traffic across disaggregated compute.
The accelerator line is built on a near-memory compute architecture Qualcomm calls High Bandwidth Compute, or HBC, which integrates the compute die with an LPDDR memory stack to break the memory wall at lower energy per token rather than relying on external HBM.
The roadmap runs from the AI200, sampling in fiscal 2026 on LPDDR5x with 43TB of capacity, to the AI250 with HBC Gen 1 in fiscal 2027, to the AI300 with HBC Gen 2 in fiscal 2028, which adds UALink and Ethernet scale up with copper and optical scale out. Qualcomm claims 4-8x better decode performance per watt for total cost of ownership and 5-7x bandwidth per watt against HBM-based solutions. It also disclosed two major hyperscaler custom silicon wins secured in the past six months, on top of legacy AlphaWave wins scaling into production, with meaningful revenue starting in the first quarter of fiscal 2027.
Customer validation brought the message home. Microsoft CEO Satya Nadella appeared to confirm that Azure will deploy the HBC accelerator, and Meta CEO Mark Zuckerberg disclosed a multi-generational collaboration for Qualcomm to supply C1000 CPUs into Meta data centers and its next-generation server fleet. Qualcomm also announced it will acquire Modular, the open AI software company whose platform claimed up to 50% faster inference in an on-stage demo, folding a vendor-neutral software layer into the silicon story.
Qualcomm’s Data Center Reentry at Investor Day 2026 Arrives Just in Time for the Inference Decode Prize
Analyst Take: Qualcomm’s breakthroughs in near-memory compute create a real technical wedge, and the AlphaWave SerDes gives it the right to win custom silicon engagements it did not have eighteen months ago. The CPU is the part still unproven. Winning a competitive CPU market hinges on co-design and on translating the company’s mobile history into the data center, and that translation has not yet been demonstrated. Whether any of it matters now that the buildout is well underway depends on how much market share Qualcomm can capture, so the place to start is the market Qualcomm is sizing.
The Market: Sizing the Overlapping Agentic and Decode-first Prizes
Global data center capital spending is on track to approach $2 trillion by 2030, with our base case landing at $1.9T, with hyperscalers accounting for about half of it. In our analysis, the share of that spend going to AI-first servers will cross 50% by 2029 and approach 75% by 2035. The accelerator silicon inside those servers is itself approaching a $1 trillion annual market by 2032.
Given Qualcomm’s late re-entry to the data center market, the number that matters is not the headline total but its long-term shape. We believe the company is well-positioned for two trillion-dollar opportunities by 2035:
- Servers tuned for agentic reasoning
- Accelerators tuned for decode
Both are growing faster than the overall market as part of workload co-design and shifting token usage to multi-step reasoning.
What Qualcomm Put on the Board: a $1 Trillion Data Center TAM Sized to FY29
The June 24 financial presentation gave the data center thesis its first hard numbers. Qualcomm sized its addressable data center opportunity at roughly $1 trillion by fiscal 2029 and split it across its four product lines. The table below sets each Qualcomm figure against our own house view.
Figure 1: Qualcomm TAM Totals Compared to Futurum Research Modeling
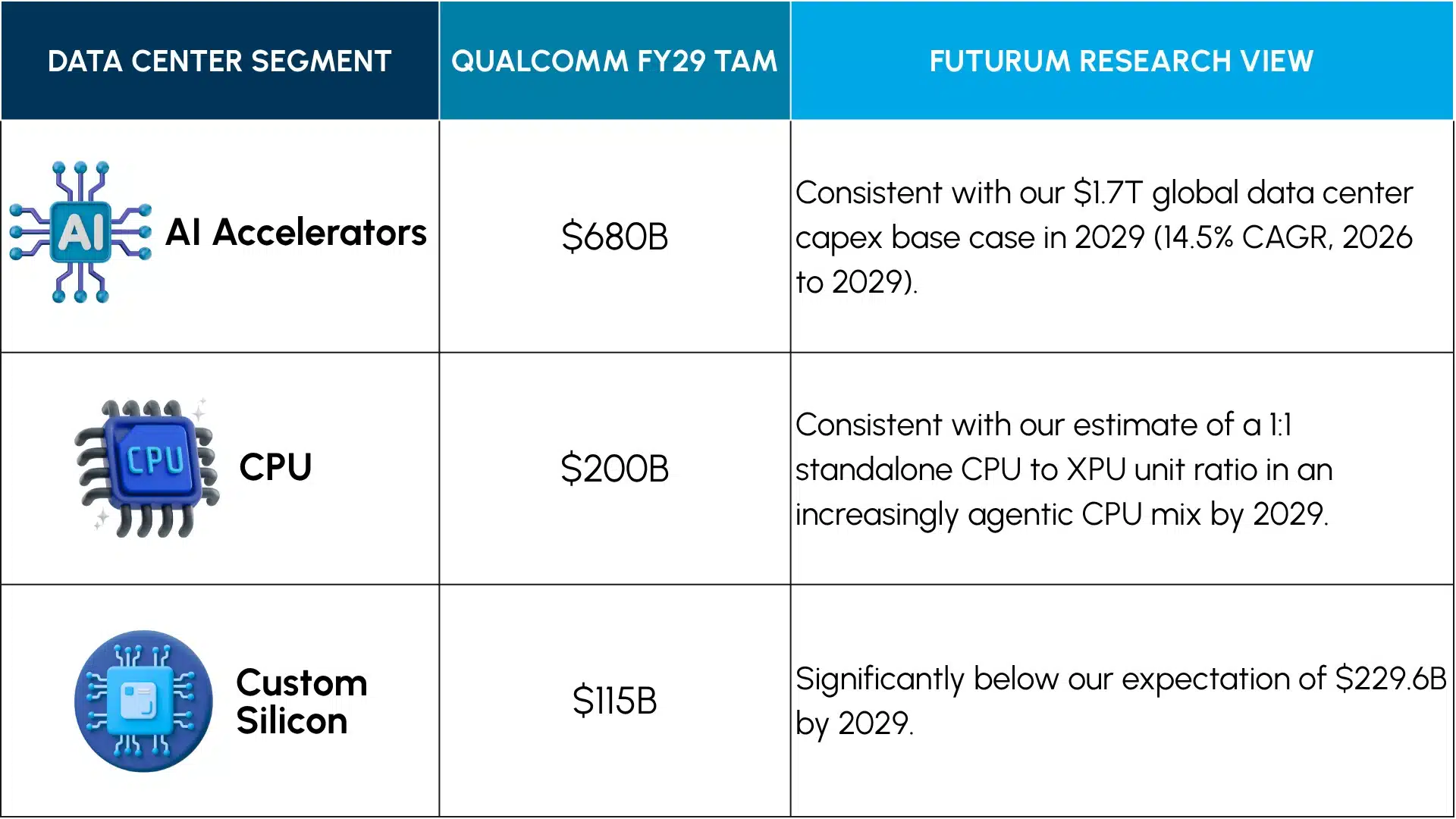
Against that TAM, Qualcomm set revenue targets of $5 billion in fiscal 2027 and $15 billion in fiscal 2029, with at least $1 billion of the fiscal 2027 figure coming from two global-scale hyperscaler customers. Management set a goal of achieving a data center share of more than 5% within five to seven years. The ramp layers by product: connectivity revenue today through AlphaWave, custom silicon from the first quarter of fiscal 2027, AI accelerator revenue in the second half of fiscal 2027, and CPU revenue in the second half of fiscal 2028. Custom silicon gross margin will run slightly below the corporate average, but will be accretive at the operating line. The same presentation raised the fiscal 2029 non-handset revenue target to $40 billion from the $22 billion set 18 months earlier, a 40%four-year CAGR from 2025, of which data center is $15 billion. Note how quickly Qualcomm’s revenue mix is already shifting towards Data Center, and how much of an impact this new vertical is expected to have on the company’s growth.
Figure 2: Updated FY29 Revenue Targets
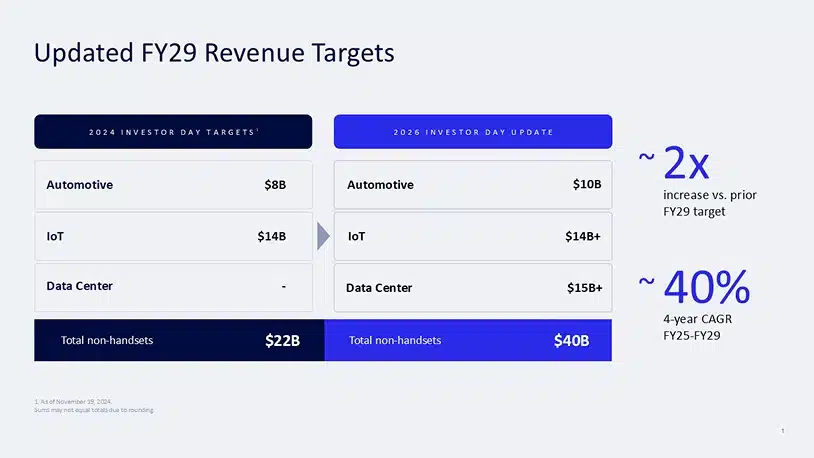
Source: Qualcomm
The attainable prize is decode acceleration, and the most novel piece of the portfolio is the near-memory HBC accelerator, not the Oryon CPU. Integrating compute with an LPDDR stack to cut energy per token is a genuine architectural departure, whereas a fast Arm server CPU, however good, competes in a red ocean.
The numbers reinforce this. Qualcomm sized the merchant accelerator line that houses HBC at $680 billion by fiscal 2029, against $200 billion for CPU and $115 billion for custom silicon. The decode prize, therefore, resides in the merchant HBC column rather than in custom silicon, where our $229.6 billion estimate offers upside relative to Qualcomm’s $115 billion. On that basis, the headline could reasonably shift over time from custom hyperscaler silicon to merchant near-memory decode acceleration, to match where the value and novelty actually lie.
Three proportions within that pool are shifting at once, and each shift moves spend toward the strengths Qualcomm is building, rather than the raw FLOPs contest Nvidia already owns.
Shift One: General Compute Gives Way to Agentic Servers
The first shift is in what the servers are for. The installed base today is dominated by general-purpose compute and by training clusters optimized around static, weight-centric HBM stacks. As reinforcement learning and continual learning become the main source of model improvement, the workload mix tilts toward systems that are continuously updated and that prize memory bandwidth and persistence over raw capacity.
Figure 3: Continual Learning Feedback Loop
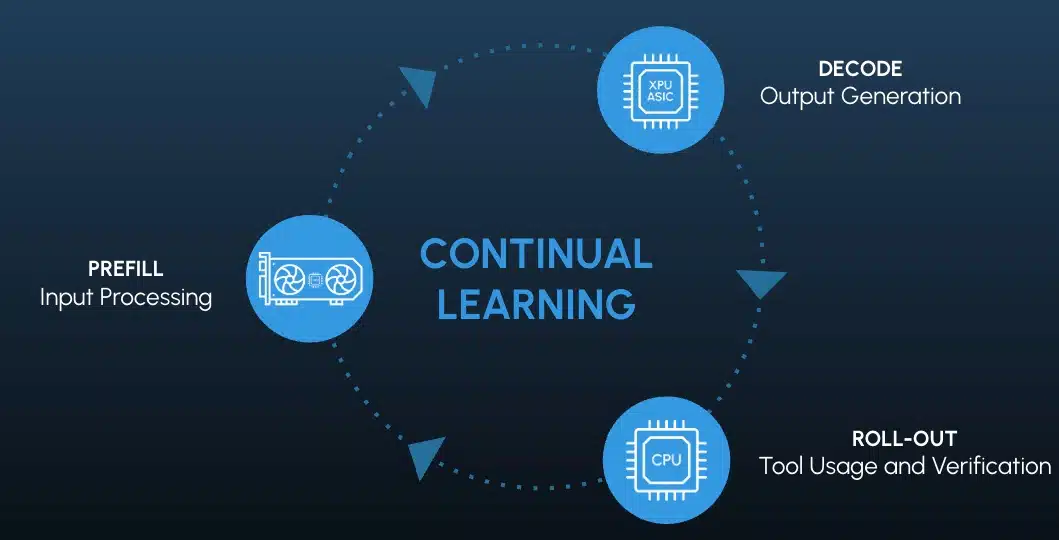
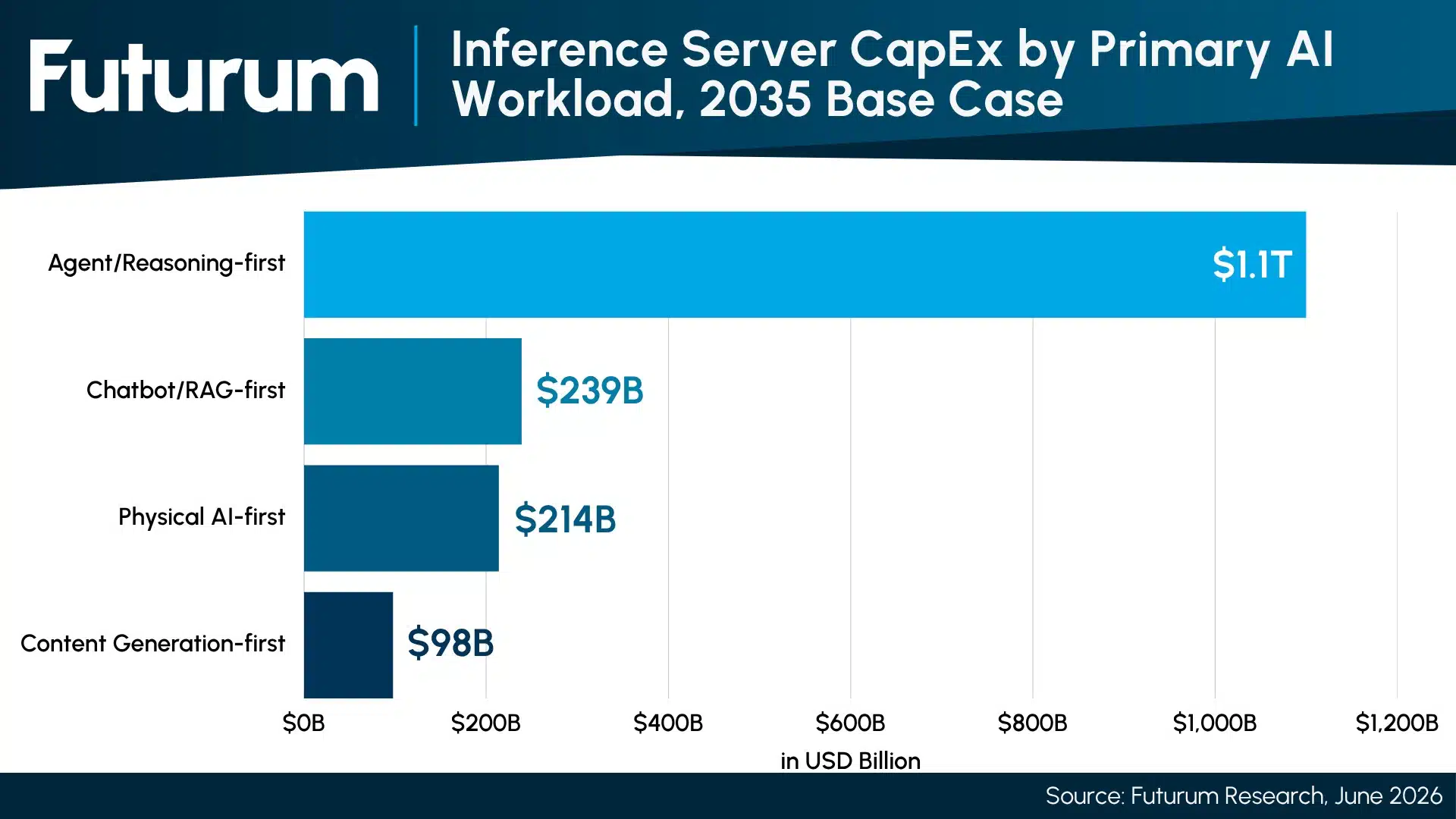
Token generation is the leading indicator. Chatbots and physical AI are both scaling token volumes quickly, but with very different compute profiles, and the lifecycle steps are disaggregating onto specialized servers rather than running on a single undifferentiated GPU box. Servers built solely for pre-training shrink as a share over time, while servers built for agentic reasoning and orchestration become the growth tier. This is the dynamic that justifies treating agent-focused servers as a standalone trillion-dollar pool rather than a slice of the training budget. In a bull case, we see servers optimized for long context and CPU-heavy inference capturing $1.8 trillion, while other inference use cases serve complementary roles.
Figure 4: Inference Server CapEx by Primary AI Workload, 2035 Base Case ($B)
Qualcomm’s right to win here is architectural. Amon has framed the data center entry as the cloud expression of an agent-orchestrator thesis, and the company’s mobile and telco lineage gives it microsecond-level scheduling between low-precision tensor cores and local I/O, exactly the coordination an orchestration tier needs. The C1000 CPU built on Oryon cores, paired with the near-memory HBC accelerator across the AI200, AI250, and AI300 line, targets the agentic-server workload as a system rather than as a faster matrix multiplier. The Modular acquisition adds the silicon-agnostic software layer that schedules work across unlike parts, which is the piece a heterogeneous orchestration tier needs and that CUDA does not provide. The caveat is that the agentic server category is still being defined in real time, so the opportunity is real, but its timing is the variable Qualcomm cannot fully control.
Shift Two: Prefill Gives Way to Decode
The second shift is inside the inference job itself. Inference splits into two phases with opposite hardware appetites: prefill, which processes the input prompt in parallel and is compute-bound, and decode, which generates output one token at a time and is bound by memory bandwidth and latency rather than FLOPs.
As models reason, the roughly 20-to-1 input-to-output token ratio that characterizes today’s single-shot workloads will invert—reasoning and agentic models generate far more than they ingest, on the order of ten times the tokens of a simple reply—which pushes the center of gravity of inference spend from prefill toward decode. In this case, the market for decode-first accelerators will exceed the combined total of the markets for training-first, prefill-first, and off-chip memory accelerators, given the need for fast memory token generators.
Cloud operators are already disaggregating the two phases onto dedicated engines so each can be optimized independently. In the decode phase, arithmetic intensity collapses, and accelerators sit memory-starved, which is precisely why decode-focused processors are being designed to hold model weights close to the arithmetic cores for reliable, low-latency generation. Decode is becoming the volume workload, and it rewards a different chip than the one that won training.
This is the cleanest fit in Qualcomm’s portfolio. Near-memory compute attacks the memory bandwidth bottleneck that defines decode, and Qualcomm’s two-decade obsession with performance per watt maps onto the segments where decode latency matters most: data retrieval, physical AI, and on-device or edge robotics. Qualcomm’s near-memory HBC accelerators, the AI200, AI250, and AI300, are positioned squarely for this workload rather than for training, integrating the compute die with an LPDDR memory stack so that weights sit next to the arithmetic cores. Qualcomm cites 18x effective memory bandwidth on the AI250 and 54x on the AI300 compared to the AI200, and 4 to 8x better decode performance per watt, resulting in lower total cost of ownership versus HBM-based GPU designs.
If Qualcomm captures even a modest share of the exponentially growing decode pool, it monetizes the part of inference that recurs forever rather than the part that happens once. The proof point still owed is benchmarked tokens-per-second-per-watt and total cost of ownership against incumbents.
Shift Three: Merchant Silicon Yields to Custom and Qualcomm Plays Both
The third shift is in who designs the chip. Merchant GPUs still dominate and will keep the majority of accelerator revenue through the decade. We forecast NVIDIA to retain 64.2% of the AI accelerator market through 2030, and GPUs at around 73.9% overall. But the growth is lopsided: custom ASIC spend is compounding in the mid-20s percent annually versus the mid-teens for merchant GPUs, custom-silicon shipments are growing several times faster than GPU shipments, and on unit volume, ASICs are projected to overtake GPUs by 2028 as Google, Amazon, Meta, and Microsoft scale their in-house parts. The market is bifurcating into a large, slower-growing merchant tier and a smaller, faster-growing custom tier, and most silicon vendors sit on only one side of that line. The custom co-design business today is concentrated almost entirely in Broadcom, Marvell, and MediaTek.
Qualcomm’s distinctive claim is that it attacks from both sides at once. It can sell merchant parts—CPU, NPU, accelerator, and a differentiated memory architecture—while also pursuing custom engagements. The Alphawave acquisition plugs the connectivity and SerDes gap that kept Qualcomm out of credible custom work, adding battle-tested IP and roughly 1,200 engineers, while Ventana’s RISC-V designs offer the customer-led, license-free optionality that hyperscalers spending at this scale increasingly want, particularly in industrial and edge, and increasingly in the data center.
The tension to watch is neutrality: a credible third-party custom partner is not supposed to compete with its own customers, and Qualcomm’s accelerator ambitions may push it toward edge AI ASICs rather than full data center AI accelerators, where it has not yet proven itself. Playing both sides is a differentiator and strategic risk in the same move.
The Modular Acquisition: An Open Software Layer Aimed Past CUDA
On the same day as the Investor Day, Qualcomm announced it will acquire Modular, an open-source AI software company led by Chris Lattner, the engineer behind LLVM, Swift, and the MLIR compiler framework on which much of modern AI tooling relies. The deal is expected to close in the second half of 2026. Modular’s platform runs models with high performance across CPU, GPU, NPU, and custom ASIC targets without rewriting code for each accelerator, and it sits on a vendor-neutral developer community rather than a single hardware stack. Qualcomm framed the asset as a silicon-agnostic compute layer spanning devices, the edge, and the data center.
This is the piece the silicon roadmap could not buy. CUDA is the reason most AI software still assumes one vendor’s GPUs, and it is excellent at dense matrix math on Nvidia hardware against a deep and mature library stack. It was never built to schedule a single job across a disaggregated, multi-vendor rack where a head node CPU, a near-memory HBC accelerator, custom silicon, and merchant GPUs each own a different stage of an agentic workload. Qualcomm’s entire data center thesis rests on that heterogeneous, disaggregated picture, and a heterogeneous rack needs software that can place, compile, and route work across unlike accelerators. Modular is that layer. Buying it gives Qualcomm a credible answer to the question every new accelerator vendor faces: how developers will target the chip on day one without a CUDA equivalent of their own.
The strategic logic is to compete where CUDA is weakest rather than where it is strongest. Qualcomm is not trying to out-CUDA Nvidia on single-vendor GPU performance. It is betting that the next phase of inference is disaggregated and multi-vendor, and that an open, portable software stack becomes the control point in that world, the way CUDA was the control point in the single GPU world. Modular also promises day-zero performance on Qualcomm’s own AI200, AI250, and AI300 accelerators, eliminating the cold-start software penalty that often slows adoption of a new silicon line.
The risk is integration and neutrality at the same time. A vendor-neutral community can lose the trust that makes it valuable if its new owner steers it toward Qualcomm silicon, so the asset’s value depends on Qualcomm keeping it genuinely cross-hardware even as it tunes for Dragonfly. This is the strongest piece of the developer-first pillar Amon described, and the one most likely to determine whether the accelerator TAM converts into revenue.
What to Watch:
- Whether the C1000 CPU posts performance-per-watt and total cost figures that hold up against AMD EPYC and AWS Graviton, rather than efficiency talking points alone
- The identities and commitment levels of the two hyperscaler custom silicon customers were disclosed on June 24, with revenue starting in the first quarter of fiscal 2027, and the rumors remain unconfirmed to date.
- The HBC near-memory accelerator roadmap and whether Qualcomm holds the yearly cadence that NVIDIA and AMD have set
- How far RISC-V customer-led optionality from Ventana reaches into the data center, where license-free regimes are gaining pull in industrial and increasingly in hyperscale environments
- Whether Qualcomm can stay a credible custom silicon partner through Alphawave while competing with the same buyers in accelerators
- Whether Qualcomm keeps Modular genuinely cross-hardware after the H2 2026 close, since a vendor-neutral software layer loses its value the moment developers read it as a Qualcomm captive, and whether it delivers the promised day-zero performance on the AI200, AI250, and AI300
You can recap the event at Qualcomm’s Investor Relations site.
Disclosure: Futurum is a research and advisory firm that engages or has engaged in research, analysis, and advisory services with many technology companies, including those mentioned in this article. The author does not hold any equity positions with any company mentioned in this article.
Analysis and opinions expressed herein are specific to the analyst individually and data and other information that might have been provided for validation, not those of Futurum as a whole.
Other Insights From Futurum:
Qualcomm Q2 FY 2026 Earnings Show Data Center Entry and Auto Strength
Qualcomm Q1 FY 2026 Earnings: Record Revenue, Memory Headwinds
Featured Image: Qualcomm
Author Information

Brendan is Research Director, Semiconductors, Supply Chain, and Emerging Tech. He advises clients on strategic initiatives and leads the Futurum Semiconductors Practice. He is an experienced tech industry analyst who has guided tech leaders in identifying market opportunities spanning edge processors, generative AI applications, and hyperscale data centers.
Before joining Futurum, Brendan consulted with global AI leaders and served as a Senior Analyst in Emerging Technology Research at PitchBook. At PitchBook, he developed market intelligence tools for AI, highlighted by one of the industry’s most comprehensive AI semiconductor market landscapes encompassing both public and private companies. He has advised Fortune 100 tech giants, growth-stage innovators, global investors, and leading market research firms. Before PitchBook, he led research teams in tech investment banking and market research.
Brendan is based in Seattle, Washington. He has a Bachelor of Arts Degree from Amherst College.

Olivier Blanchard is Research Director, Intelligent Devices. He covers edge semiconductors and intelligent AI-capable devices for Futurum. In addition to having co-authored several books about digital transformation and AI with Futurum Group CEO Daniel Newman, Blanchard brings considerable experience demystifying new and emerging technologies, advising clients on how best to future-proof their organizations, and helping maximize the positive impacts of technology disruption while mitigating their potentially negative effects. Follow his extended analysis on X and LinkedIn.





