
Analyst(s): Brendan Burke
Publication Date: June 9, 2026
What is Covered in This Article:
- The Intel-vs-NVIDIA agentic CPU divergence
- Connectivity and inference decode bottlenecks addressed by optics and workload disaggregation
- PC reinvention and the AI workstation wave
- Other winners and the outlook for industry responses
The Event—Major Themes & Vendor Moves: COMPUTEX 2026 ran June 1–5 in Taipei under the theme “AI Together,” drawing 111,312 buyers and visitors from 152 countries. The keynote series from Qualcomm, Marvell, Intel, and NXP pulled 6,000 attendees, while the COMPUTEX Forum gathered 28 leaders for sessions across 13,200 visits, and InnoVEX hosted 500+ startups. Founded in 1981, the show has become the global benchmark exhibition for AI and the Taiwanese supply chain.
Intel and NVIDIA told the most complete agentic CPU co-design stories—and diverged sharply. Intel’s keynote argued agents will run mostly on CPUs, making agents per rack a defining metric, with a single liquid-cooled Xeon 6+ rack reaching 36,864 cores and up to 150,000 agents per rack. To take the thesis to a systems level, Intel advanced Rackscale Blueprints with Foxconn and SambaNova and stood up the ‘Vector Core Compute’ inference cloud. In a Thursday live demo, SambaNova showed an agentic data-analysis task spending just 2 of 45 seconds on the GPU, with CPUs and RDUs finishing the job.
NVIDIA drove home the need for high-speed CPUs. Jensen Huang waded into chip floorplan and instructions per clock as the Vera CPU’s advantage for agentic speed in reinforcement-learning sandbox loops, all governed by the DSX software control plane and a tokens-per-megawatt metric.
Beyond the two, Cadence and Marvell earned Jensen’s acclaim for internal R&D, and heterogeneous systems lifted the content of Astera Labs networking chips, Lattice FPGAs, and Navitas power ICs. The Taiwanese supply chain may have been the biggest winner of all, with universal applause for their collaboration and support for innovation, encouraging global expansion to strengthen supply chains.
COMPUTEX 2026: Are Agentic CPUs Rivals or Complements?
Analyst Take: COMPUTEX advanced the role of conventional computing form factors, including CPUs and PCs, while accelerating momentum for decode-only accelerators and silicon photonics. In their keynotes, Intel and NVIDIA clashed over the same agentic CPU socket, the former betting on high core count and the latter on high frequency. The two agentic CPU theses target different points of the agent lifecycle, which means the chips are more likely to prove complementary than substitutable. Intel’s Xeon 6+ optimizes for the density and concurrency of enterprise inference. NVIDIA’s Vera, with its 88-core Olympus design and NVLink-C2C tie to Rubin, optimizes for the speed of orchestration and the tight reinforcement learning sandbox loops that compound a training advantage.
Two Agentic CPU Theses. Both Winners?
Both companies are really expanding the same pie. Futurum’s 1H 2026 Data Center Semiconductors Forecast puts Intel at 45.3% data center CPU share against Arm-based alternatives at 25.0%, with the market on pace to grow 38.8% in 2026 on AI inference demand. Agentic coding workloads can generate up to 1,000x more tokens than single-turn interactions, and that pressure rewards Intel’s CPU for orchestration density and NVIDIA for task completion speed as part of budget-sensitive training runs. NVIDIA’s claimed 1.8x task-completion advantage over x86 is workload-specific to the RL lifecycle, not a general-purpose knockout.
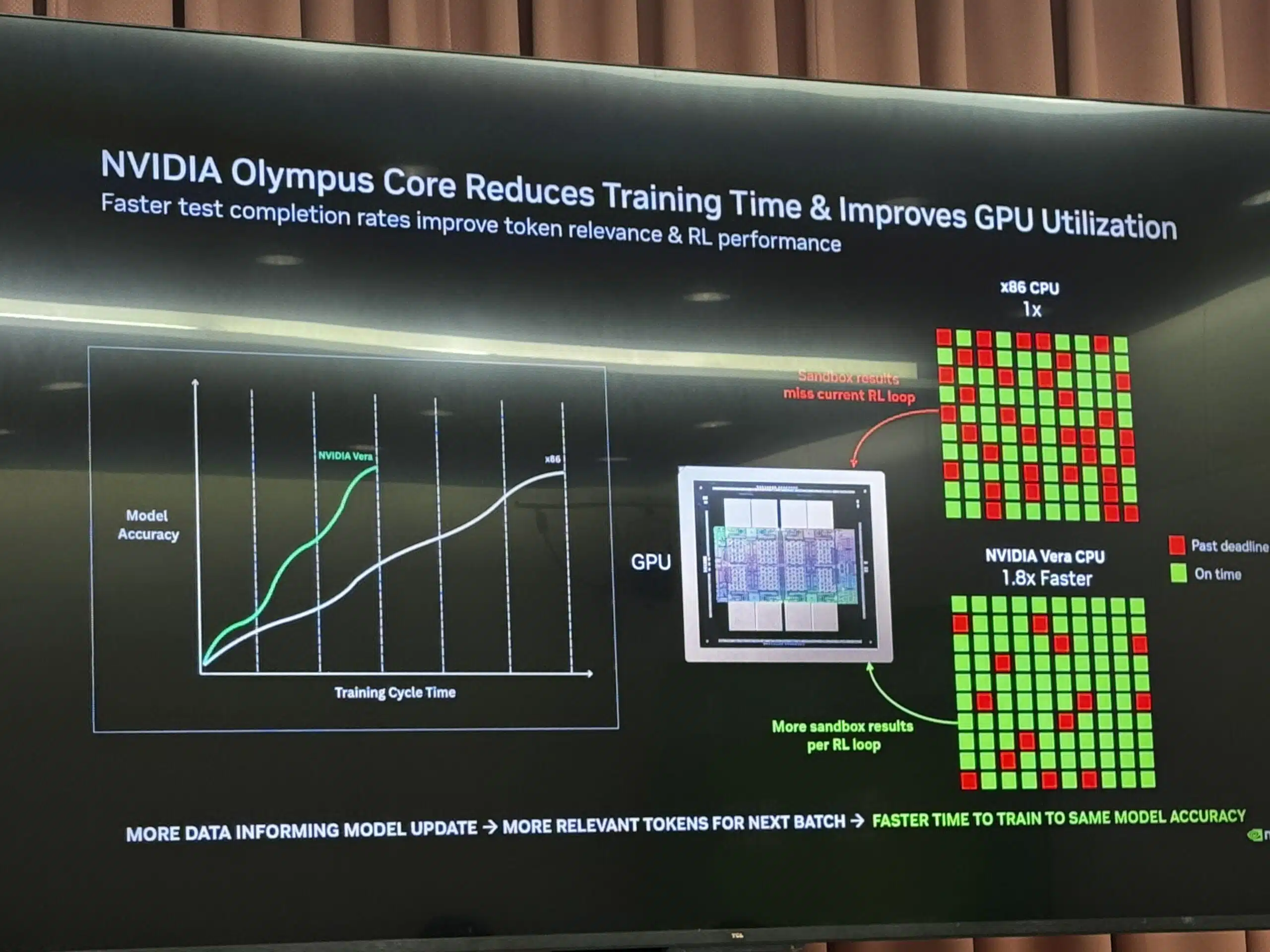
Vera compounds NVIDIA’s training advantage for the RL era, while Intel serves the broad enterprise inference install base, and both are positioned to evolve with the field. Both systems are likely to find roles in an expanding agentic CPU TAM that rewards both an inference-density design and a speed-optimized design. COMPUTEX’s ‘AI Together’ slogan was about more than international collaboration. Systems designers who take an AI lab perspective on co-design will be the ones ready for the next leg of hypergrowth.
Photonics and Decode-Only Inference Attack Networking Bottlenecks
The sharper lesson from COMPUTEX 2026 is that the binding constraint on agentic inference is not CPU compute at all but data movement for MoE models across scale-up networking and disaggregated accelerator integration. Marvell CEO Matt Murphy built his keynote on the question of what defines AI infrastructure performance and answered connectivity, calling AI scaling “fundamentally a connectivity challenge” and naming connectivity the next bottleneck after compute and memory. He framed the copper wall that we discussed in our January Techstrong Predict 2026 video (registration required) at roughly 2.5 meters of reach at 200 Gbps, a forcing function for optics, including co-packaged optics (CPO), inside the rack.
He backed this bold claim with a 100T Ethernet switch, a 1.6-terabit 2nm coherent solution, a 51.2T CPO switch, and a $2 billion NVIDIA partnership spanning optics, photonics, and NVLink Fusion. Astera Labs weighed in on the case from its energetic booth, demonstrating an end-to-end optical PCIe 6 link over its Scorpio X-Series fabric switch and linear pluggable optics at up to 50 meters, aimed squarely at the KV-cache offloading that sits in the critical path of every token in high-context inference.
SambaNova attacks the other half of the problem. Inside the newly announced inference-only Vector Core Compute cloud in partnership with Intel, Cambium Capital, and Vista Equity Partners, inference disaggregation splits Blackwell prefill and SambaNova decode, offloading the memory-bound decode stage to RDUs so GPUs are freed to create the KV cache. SambaNova did a live demo of the newly announced Vector Cloud Compute’s hybrid AI cluster, showing an agentic data analysis task spending just 2 out of 45 seconds on GPU (still most of the tokens) with CPUs and RDUs finishing the job. The system achieved 2-3x speed-up over GPU clusters alone, according to their testing. Connectivity, decode, and CPU orchestration will need to be co-designed to advance as one system to resolve acknowledged bottlenecks in GPU inference.

RTX Spark Reinvents the PC as an Agentic Relief Valve
The agentic CPU story went far beyond the rack to the edge, inviting closer scrutiny from consumers. NVIDIA, MediaTek, and Microsoft used the week to reinvent the PC for on-device agents with RTX Spark, a 1-petaflop Windows superchip pairing a Blackwell RTX GPU with a 20-core Grace CPU and up to 128GB of unified memory, alongside the GB300-based DGX Station for Windows for the enterprise desk. The pitch can push always-on agentic inference onto hardware users to redistribute the fastest-growing load away from strained data center campuses.
A broad AI workstation wave is forming around it—Acer, ASUS, Corsair, Dell, GIGABYTE, HP, Lenovo, Microsoft Surface, and MSI—while AMD-based workstations broaden the category beyond the NVIDIA stack. The caveat is that memory bandwidth, not headline FLOPS, will decide whether local agents feel like teammates, and tight memory budgets are already applying the pricing pressure that the AI workstation message still has to answer.
What to Watch:
- Qualcomm signaled a fuller picture at its Investor Day on June 24, where its agentic and edge roadmap should sharpen against the CPU-centric narrative from Intel and NVIDIA.
- AMD’s Advancing AI, a month later, should bring the edge-to-cloud vision together and test where the CPU-to-GPU ratio actually lands for agentic data centers.
- The AI workstation message needs refinement as memory constraints apply pricing pressure.
- Independent validation of Vera’s 1.8x RL sandbox speedup claim.
- Whether Vector Core Compute’s disaggregation economics hold across many customers and models once Blackwell prefill and SambaNova decode are fully priced in.
Read more about COMPUTEX 2026 on the COMPUTEX website.
Disclosure: Futurum is a research and advisory firm that engages or has engaged in research, analysis, and advisory services with many technology companies, including those mentioned in this article. The author does not hold any equity positions with any company mentioned in this article.
Analysis and opinions expressed herein are specific to the analyst individually and data and other information that might have been provided for validation, not those of Futurum as a whole.
Other Insights From Futurum:
Intel’s COMPUTEX Keynote Reframes an Iconic Company as a Silicon-to-Systems AI Lab
NVIDIA Engineers the Agentic Data Center with DSX Software Control and Vera CPU Acceleration
Intel Xeon 6+ Targets Agentic AI Density With 288 E-Cores on Intel 18A
Featured Image: COMPUTEX
Author Information

Brendan is Research Director, Semiconductors, Supply Chain, and Emerging Tech. He advises clients on strategic initiatives and leads the Futurum Semiconductors Practice. He is an experienced tech industry analyst who has guided tech leaders in identifying market opportunities spanning edge processors, generative AI applications, and hyperscale data centers.
Before joining Futurum, Brendan consulted with global AI leaders and served as a Senior Analyst in Emerging Technology Research at PitchBook. At PitchBook, he developed market intelligence tools for AI, highlighted by one of the industry’s most comprehensive AI semiconductor market landscapes encompassing both public and private companies. He has advised Fortune 100 tech giants, growth-stage innovators, global investors, and leading market research firms. Before PitchBook, he led research teams in tech investment banking and market research.
Brendan is based in Seattle, Washington. He has a Bachelor of Arts Degree from Amherst College.





