
Analyst(s): Brad Shimmin
Publication Date: June 11, 2026
Document #: AIOBS202605
As artificial intelligence accelerates from generative assistance to autonomous execution, legacy data infrastructure faces a massive reckoning. Major database providers are actively rearchitecting their platforms to support the high-concurrency, strictly consistent, and multi-tiered memory requirements of autonomous agents. Here are the key takeaways as enterprises navigate this architectural transition.
Key Points
- Autonomous read-write agents require databases to evolve from passive systems of record or analysis into active systems of action capable of running continuous decision-making loops.
- Multi-tiered memory, zero-copy speculative branching, and serializable transaction isolation have emerged as mandatory capabilities to prevent cascading operational failures.
- Established generalists and specialized context engines are rapidly decoupling compute from storage and embedding robust security protocols to capture multi-agent workloads safely.
Recommendations
- Embed Native Data Security and Access Controls: Vendors must relocate security enforcement away from fragile application-layer prompts and push it directly into the database engine. Implementing native SQL firewalls, dynamic data masking, and strict row-level access controls ensures that autonomous agents cannot execute unauthorized actions or leak sensitive information.
- Prioritize Standardized Interoperability and Tool Discovery: To remain competitive, database providers should integrate universally recognized frameworks such as the Model Context Protocol (MCP) directly into their platforms. Moving away from hallucination-prone text-to-SQL logic to instead use schema-first, server-side entity navigation allows agents to interact with operational data safely and predictably.
- Decouple Compute for Elastic, Agent-Scale Economics: Vendors must architect their platforms to support extreme horizontal scalability and serverless bursting. Because multi-agent systems can generate volatile, machine-speed transaction spikes, decoupling compute from storage enables organizations to scale resources dynamically and flatten the total cost of ownership curve during idle periods.
What You Need to Know
The database industry is rapidly transitioning toward active, intelligent storage environments equipped with real-time change data capture, speculative execution sandboxes, and highly structured agentic memory capabilities.
As artificial intelligence is evolving rapidly to tackle autonomous execution, we are observing a clear progression in AI commerce from read-only chatbots to read-write autonomous agents capable of negotiating and executing complex transactions across enterprise environments without human intervention. And this evolution has exposed notable gaps in data infrastructure. Databases designed for predictable, human-centric queries are faltering under the always-on, high-velocity demands of autonomous fleets.
Analysis
The rapid maturation of autonomous artificial intelligence has exposed a fundamental architectural mismatch in modern enterprise software. Historically, database management systems were designed as passive systems of record or reactive systems of intelligence. These engines were engineered to handle structured transactional flows or process historical analytics at a human scale, waiting for explicit user queries to return static datasets. By evaluating repeated queries over time, advanced database engines could readily adapt to handle spikes in usage, parceling out parallelized cluster access according to well-reasoned, highly structured query plans.
Agentic systems completely toss these practices and technologies out the window. Today, as organizations deploy fleets of autonomous agents, this foundational design is struggling to support the weight and unpredictability of machine-speed execution. Agents run continuous decision-making loops, monitor streaming event queues, and constantly write execution states, often according to goal-driven processes that continuously morph and evolve. This always-on operational envelope multiplies transactional and query volumes by factors of 10 to 100.
The modern database must, therefore, shed its historical role as a passive filing cabinet and transform into an active execution environment (e.g., a true system of action) that enables autonomous entities to perceive operational states, plan complex workflows, deduce optimal steps, and execute transactions, all with high concurrency.
Adopting Active Storage and Splitting Data Gravity
According to the Futurum Research 2026 Key Issues & Predictions report, AI commerce is transitioning from read-only reasoners to autonomous actors capable of fully participating in business processes, not just reading but actually writing back to the corporate system record. Furthermore, such agents possess the authority to negotiate and execute transactions across cloud marketplaces, back-end systems, and even user desktop environments without human intervention. While many companies see this as a transformational capability, the elevated responsibility required of agents means the cost of a model hallucination or a data retrieval error can transform from a minor user annoyance into a substantial financial liability.
To mitigate this risk, enterprise data infrastructure is rapidly evolving from passive storage toward active storage. Major vendors are simultaneously pushing data gravity up the stack in the form of metadata while also pushing data processing down to the storage layer, thereby allowing AI agents to take action directly where the data resides. There are good reasons for this, depending on future project demands and existing data estate investments. Moving the compute layer to the storage layer natively embeds real-time data discovery and vector acceleration into the execution path. This architectural choice successfully bypasses application-layer network latency. It can also significantly mitigate the security risks associated with exfiltrating sensitive data to AI models.
Multi-Tiered Memory and the Death of Split-Stack Sprawl
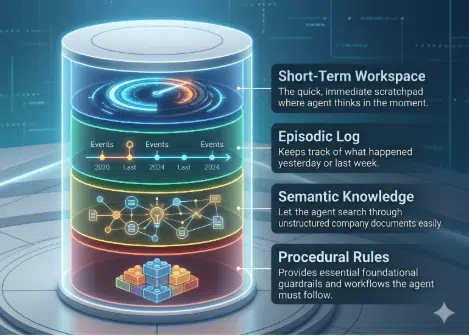
One of the primary drivers of this architectural “re-think” is memory. Where should agentic memory live – in code, within markdown files, within an in-memory database? That will again depend on project demands and available investments. Regardless of approach, agentic memory must be managed the same as any data estate asset. Why? To operate autonomously over long horizons, an AI agent requires a highly sophisticated memory architecture natively managed within the database. To function effectively, this memory architecture splits into four distinct operational layers (see Figure 1).
Figure 1: The Four Tiers of Agentic Memory
Source: Futurum Research, May 2026
Moving away from the messy, pieced-together infrastructure of the past, modern systems consolidate all four ways an AI agent “remembers” into a single, reliable home. This unified approach removes the headaches of keeping different systems in sync and helps ensure agents operate safely and predictably.
First, short-term memory acts as the immediate workspace. It preserves dialogue turns, intermediate tool outputs, and execution states within an active thread, requiring transient storage with sub-millisecond write performance. Second, episodic memory logs the history of conversations and sequential event logs across separate sessions, enabling the agent to recall prior interactions and learn from past mistakes. Third, semantic memory manages dense vector representations of unstructured knowledge, allowing fuzzy similarity searches over enterprise documents for Retrieval-Augmented Generation (RAG). Finally, procedural memory stores structured workflows, operational constraints, and task instructions.
Enterprise developers initially attempted to meet these requirements through a “split-stack” pattern, stitching together disparate systems, utilizing Redis for short-term state, Pinecone for semantic retrieval, and PostgreSQL for transactional workflows. This approach creates significant integration debt and recovery complexity, increases the system’s security surface, and risks severe consistency failures.
The industry is now rallying around a much more unified stack pattern. Consolidating all four memory layers into highly elastic, multi-model backends simplifies access control and eliminates external synchronization pipelines. Relational platforms with vector extensions or multi-model NoSQL engines can natively store structured states, conversational logs, and vector embeddings in a single cluster under a unified security policy.
Strong Consistency: Solving the Write-Back Bottleneck
The architectural reliance on eventual consistency represents a critical vulnerability in multi-agent systems. When a standard web application reads slightly stale data, the user might see an outdated “like” count on a social media post. When a parallelized autonomous agent reads out-of-order or incomplete inventory data, it treats that data as absolute truth, translating minor database anomalies into cascading physical or transactional errors.
The inability to rely on underlying data consistency is actively stalling enterprise deployments. According to the 1H 2026 Data Intelligence, Analytics, and Infrastructure Decision Maker Survey Report, 24.6% of respondents cite the inability of AI agents to write back to systems of record as a top infrastructure bottleneck. If multiple agents run in parallel to allocate stock or adjust pricing, eventually consistent replica nodes may report inventory that has already been claimed by a parallel agent.
Consequently, strong serializable consistency and ACID transactional guarantees are transitioning from relational design preferences into mandatory infrastructural requirements for agentic systems. This is no longer a relational database problem. It’s an agentic problem. Just as database engines do, agentic systems demand concurrency and consistency at scale under all conditions, including when under duress (broken transactions, conflicting actions, etc.). To illustrate, serializable isolation can prevent issues such as double-allocations by ensuring that every transaction executes as if it were the only operation on the system, guaranteeing predictable correctness even under extreme agent concurrency.
Speculative Branching: Safely Breaking the Database
Autonomous agents frequently also require isolated environments to test generated code, evaluate complex multi-step plans, or execute speculative mutations without risking the integrity of production data. Granting an operational model the authority to run raw queries directly against a live database in 2026 is a total non-starter, as it introduces severe data corruption risks.
This demand has catalyzed the development of speculative sandbox environments powered by Copy-on-Write (CoW) storage architectures. For example, databases such as Databricks Lakebase and Tiger Data’s TimescaleDB allow developers and agents to instantly fork a running production database. Because the fork operates at the block storage level, creating 50 branches of a 1-terabyte database does not consume 50 terabytes of storage. The branches instead share the parent pages and only persist the new mutations. This mathematical efficiency enables agents to programmatically spin up ephemeral branches, test multiple solution paths against real production data, commit only the successful branch, and discard the sandbox in seconds.
Standardized Protocols and Schema-First Navigation
Historically, developers exposed databases to large language models (LLMs) via naive Text-to-SQL pipelines. This approach frequently fails because raw tables lack semantic context, leading models to misunderstand schemas, hallucinate table names, and generate highly unoptimized queries that crash production servers.
Agents require a database they can navigate predictably. This necessity has sparked the rapid adoption of standardized interfaces, most notably the MCP. Operating as a database gateway (a high-level entry point), MCP standardizes how models communicate with data sources using universal, secure interfaces. According to the Futurum 1H 2026 DIAI Market Sizing & Five-Year Forecast Report, 20% of respondents interested in agentic AI are already running MCP in production. This validates a broad architectural move away from fragile prompt engineering toward schema-first, server-side entity navigation of data. This move also underscores the importance of a robust semantic (metadata) layer that standardizes and disambiguates meaning across the corporate data estate.
Instead of guessing at raw SQL code, agents can utilize auto-generated tools to browse structured business entities, such as customer profiles or order tickets, safely governed by the data catalog and the underlying database’s internal logic and row-level filtering rules.
The Competitive Landscape: Generalists vs. Specialists
How are these technologies, practices, and tools entering the market? The enterprise data landscape features intense competition among generalist platforms and specialized context engines, all racing to capture the lucrative workloads of autonomous agent fleets (see Figure 2).
Figure 2: Evaluating the Agentic Database Landscape
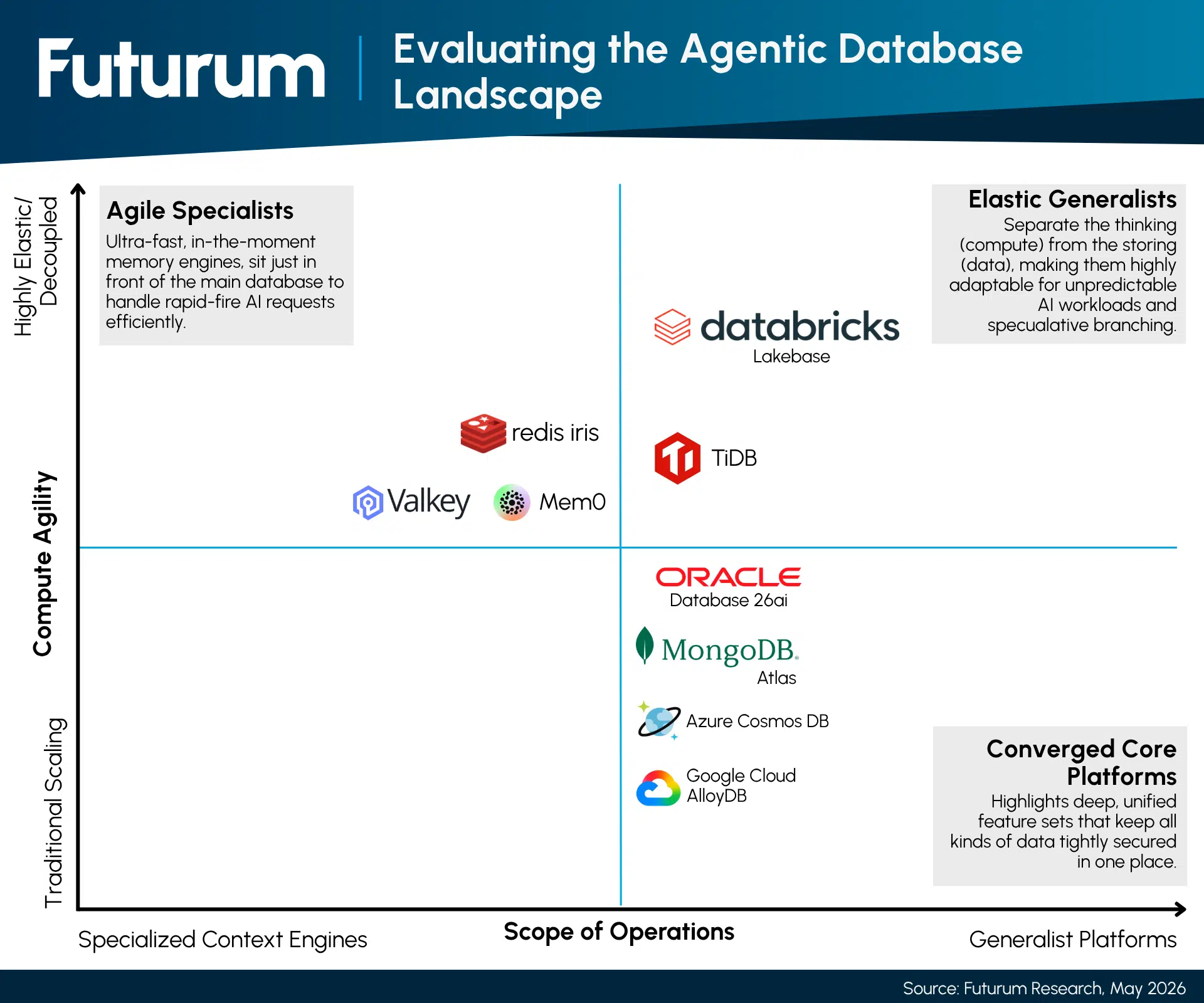
Providers are tackling the AI challenge from different, yet equally creative, angles. While generalists focus on bringing all data types under one secure roof, specialized context engines are built to handle the lightning-fast, high-volume memory demands of active AI fleets. There is ample room for both approaches as organizations figure out what works best for their unique setups.
Source: Futurum Research, May 2026
Oracle has engineered its flagship offering, Oracle AI Database 26ai, to serve as a unified memory core. Avoiding the architectural sprawl of specialized vector stores, Oracle consolidates JSON documents, relational tables, time-series, and spatial data within a single converged engine. A defining feature is the company’s new Private Agent Factory, a visual orchestration platform embedded directly within the database. This allows enterprises to build and manage trusted AI agents securely on-premises or within their own cloud tenancy, ensuring sensitive data is never exposed to public model APIs. By incorporating a native SQL firewall to thwart injection attacks and enforcing strict cell-level access controls, Oracle delivers the robust enterprise-grade security that multi-agent systems require.
Databricks approaches the agentic workload similarly through its Lakebase serverless PostgreSQL engine. Addressing the historical friction between operational and analytical data, Lakebase decouples compute from storage to support highly volatile agent traffic. Utilizing lightweight, ephemeral compute running atop durable data lake storage, Databricks facilitates the aforementioned Git-style database branching, empowering agents with zero-cost sandboxes for speculative planning.
In the NoSQL domain, MongoDB Atlas leverages the inherent flexibility of the document model to manage the highly variable, semi-structured state of AI agents. Through deep technical integrations with frameworks such as LangGraph, MongoDB provides the LangSmith Checkpointer. This unique integration collapses checkpoint writes across all enterprise agent deployments into a single, shared Atlas cluster, allowing agents to pause, rewind, and resume complex tasks reliably. Azure Cosmos DB similarly utilizes its globally distributed NoSQL engine, paired with DiskANN indexing, to deliver low-latency semantic search and thread-safe document checkpointing at a massive scale.
Likewise, Google Cloud has optimized AlloyDB AI for agentic operations by implementing its proprietary ScaNN index, delivering dramatic performance advantages over standard PostgreSQL Hierarchical Navigable Small Worlds (HNSW) indices when scaling into the billions of vectors. AlloyDB AI also integrates fully managed remote MCP servers, enabling secure tool discovery, and exposes native in-database AI functions so agents can summarize or analyze sentiment entirely within the storage plane, eliminating network round-trips entirely.
Is there a single winning entry or approach? As with most IT endeavors, that depends very much on what a business intends to build and upon which data platform they intend to build that solution. If the company is just beginning its agentic journey with minimal existing infrastructure to contend with, the solution will likely favor a composable assemblage of best-of-need tools. Conversely, if the company already possesses a deep investment in existing data warehouse or lakehouse solutions, such as those reviewed in Futurum’s Data Intelligence Platforms Signal report, there’s no rush to move away from these established investments, given the massive investments made by Google, Databricks, Snowflake, Microsoft, AWS, and others to support agentic database concerns.
Deep Dive: Context Engines and Open-Source Agility
In parallel with generalists, specialized engines are aggressively targeting unique problems, such as real-time context bottlenecks. Redis Iris operates as an active context engine sitting strategically between the AI agent and the underlying system of record. By utilizing Redis Data Integration (RDI) for ultra-low-latency Change Data Capture (CDC), Redis ensures agents have sub-millisecond access to real-time events without overwhelming the primary transactional database. Redis pairs this with its LangCache capability, which performs semantic caching. Instead of requiring exact string matches, it connects incoming queries based on semantic intent, retrieving responses directly from memory to bypass redundant LLM inference calls and slash API costs.
Likewise, in the open-source ecosystem, the combination of vector stores such as Valkey and the agent memory frameworks such as Mem0 provides a highly scalable, structured in-memory context architecture. Valkey acts as the ultra-low-latency persistent storage plane, while Mem0 handles the cognitive extraction and deduplication of memories. By leveraging hash-level data lifecycles to prune obsolete contexts, Valkey resolves memory conflicts without introducing latency bottlenecks in the agent’s execution loop.
For organizations demanding extreme horizontal scalability, distributed SQL platforms such as TiDB treat the database as a highly programmable, S3-backed substrate. Implementing multidimensional scaling and rapid, second-level provisioning, TiDB addresses the existential cost barriers that arise when fleets of agents indiscriminately spin up thousands of ephemeral execution environments. Its distributed architecture provides the necessary transactional guarantees to safely process the concurrent state transitions typical of complex frameworks.
Conclusion: Architectural Governance and the Path Forward
The database market is taking two distinct, equally fascinating paths to handle the unpredictable weight of autonomous AI workloads. In one direction, platforms are pulling everything inward. We see vendors creating tightly bound, vertically integrated cores that natively handle everything from vector math to strict security without requiring external plugins. In the other direction, the underlying technology is exploding outward. By snapping the rigid link between where data lives and where it is processed, developers are gaining the freedom to build highly creative, modular data estates that stretch and adapt the moment a fleet of AI agents spins up.
This fork in the road forces organizations to rethink how they evaluate their infrastructure. Judging a new system solely on standard storage costs or human-scale query performance is no longer sufficient. Buyers need to begin evaluating platforms based on their “agent readiness.”
The focus is shifting from how much information a system can hold to how intelligently it can govern automated actions. IT teams should ask whether a database can instantly spin up a safe, isolated sandbox for an AI to test a complex workflow, or whether it has internal guardrails to prevent a hallucinating model from overwriting critical inventory data.
Ultimately, this transition from passive storage to active participation marks an incredibly exciting chapter for enterprise architecture. Whether a company chooses the unified comfort of a highly optimized stack or the creative flexibility of a decoupled environment, the resulting infrastructure will be far more resilient and capable. The great news is that companies are increasingly building systems that do more than just remember what happened yesterday. Instead, they’re building systems actively helping figure out what to do tomorrow. For organizations willing to embrace this shift, the next generation of data infrastructure provides a remarkably powerful canvas for innovation. In the meantime, Futurum will keep a close eye on this space with future research into competitive solutions, evaluating how quickly and fully market leaders deliver on the promise of agentic AI through capabilities such as sandboxing, write-back integrity, schema-first navigation, etc.
What to Watch
- The Rise of Agent Control Planes: As multi-agent frameworks proliferate across enterprise departments, watch for the rapid development of unified control platforms designed to manage agent identity, classify operational risk, and oversee execution lifecycles across diverse cloud environments.
- Inference Economics and Data FinOps: Monitor how organizations grapple with the bursty, high-frequency compute demands of agentic workflows. We expect a surge in specialized “Data FinOps” solutions aimed at intelligently caching semantic queries and optimizing context windows to control runaway token expenditures and cloud infrastructure costs.
- Convergence of Vector and Relational Operations: Keep an eye on the continued commoditization of standalone vector databases. As platforms such as PostgreSQL (via pgvectorscale) and Oracle enhance their native hybrid search capabilities, the market will strongly favor converged systems over isolated vector silos to reduce architectural complexity and synchronization debt.
Other Insights from Futurum
Futurum Agent Control Plane Framework: A Reference Model for Production AI Agents
Semantic Layer Set to Become the Next Piece of Critical Infrastructure
The Rise of Sovereign Clouds Amidst a Fractured Global Climate
Is the Open Semantic Interchange the Treaty AI Needs to Deliver Value?
Disclosure: Futurum is a research and advisory firm that engages or has engaged in research, analysis, and advisory services with many technology companies, including those mentioned in this article. The author does not hold any equity positions with any company mentioned in this article.
Analysis and opinions expressed herein are specific to the analyst individually and data and other information that might have been provided for validation, not those of Futurum as a whole.
Read the full Futurum Group Disclosure.
Author Information

Brad Shimmin is Vice President and Practice Lead, Data Intelligence, Analytics, & Infrastructure at Futurum. He provides strategic direction and market analysis to help organizations maximize their investments in data and analytics. Currently, Brad is focused on helping companies establish an AI-first data strategy.
With over 30 years of experience in enterprise IT and emerging technologies, Brad is a distinguished thought leader specializing in data, analytics, artificial intelligence, and enterprise software development. Consulting with Fortune 100 vendors, Brad specializes in industry thought leadership, worldwide market analysis, client development, and strategic advisory services.
Brad earned his Bachelor of Arts from Utah State University, where he graduated Magna Cum Laude. Brad lives in Longmeadow, MA, with his beautiful wife and far too many LEGO sets.






