
Analyst(s): Brendan Burke
Publication Date: April 27, 2026
Meta has agreed to deploy AWS Graviton processors at scale, making it one of the largest Graviton customers in the world and expanding a long-standing cloud partnership. The deal underscores a broader infrastructure shift in which CPU-intensive agentic AI workloads are creating demand patterns distinct from GPU-centric model training.
What is Covered in This Article:
- Meta’s large-scale Graviton deployment agreement with AWS
- The rising CPU intensity of agentic AI workloads
- Graviton5’s architectural advantages for real-time reasoning tasks
- Strategic implications of compute diversification at hyperscale
- Energy efficiency as a differentiator in AI infrastructure deals
The News: Meta has signed an agreement with Amazon Web Services to deploy Graviton processors at scale, starting with tens of millions of Graviton cores and with the flexibility to expand as Meta’s AI capabilities grow. The deal builds on a long-standing relationship between the two companies, including Meta’s existing use of Amazon Bedrock, and positions Meta as one of the largest Graviton customers in the world. The deployment will power various workloads at Meta, including infrastructure supporting the company’s agentic AI efforts, which require handling billions of interactions while coordinating complex, multi-step agent workflows.
“This isn’t just about chips; it’s about giving customers the infrastructure foundation, as well as data and inference services, to build AI that understands, anticipates, and scales efficiently to billions of people worldwide,” said Nafea Bshara, vice president and distinguished engineer at Amazon Web Services.
Santosh Janardhan, head of infrastructure at Meta, noted that “diversifying our compute sources is a strategic imperative” and that Graviton enables the company to “run the CPU-intensive workloads behind agentic AI with the performance and efficiency we need at our scale.”
Meta’s Graviton Bet Reframes the CPU as an AI Workhorse
Analyst Take: Meta’s decision to deploy tens of millions of AWS Graviton cores lends gravity to Andy Jassy’s comment in his 2025 Letter to Shareholders that two large AWS customers asked if they could buy all Graviton instance capacity in 2026. While the industry’s attention has been overwhelmingly fixed on GPU procurement for model training, this deal highlights the distinct and growing compute demands created by agentic AI workloads such as real-time reasoning, code generation, ad retrieval, content generation, product recommendations, and multi-step task orchestration.
AWS Graviton5, built on 3-nanometer chip technology with 192 cores and a 5x larger cache than its predecessor, is purpose-built for exactly these CPU-intensive patterns. Signal65 testing finds that Graviton4 achieves up to 205% more tokens per dollar running Llama-3.1-8B with a small input/small output compared to AMD and over 214% for Intel. The agreement reinforces AWS’s strategy of using custom silicon to differentiate its cloud platform, a playbook that has now attracted commitments from both Meta and Anthropic.
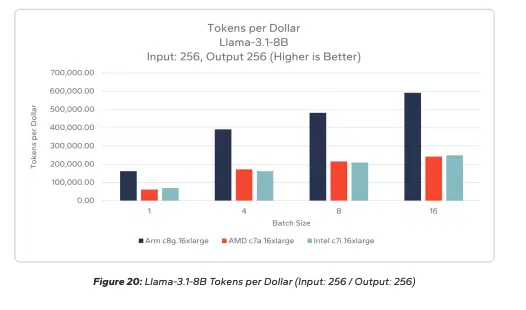
Agentic Workloads Are Rewriting Infrastructure Requirements
The rise of agentic AI is introducing infrastructure requirements that do not map neatly onto the GPU-centric architectures that dominated the first wave of generative AI investment. Agents that reason through multi-step tasks, generate and execute code, conduct real-time search, and orchestrate workflows across distributed systems demand sustained, high-throughput CPU compute rather than the burst-parallel processing GPUs excel at. Meta’s decision to source tens of millions of Graviton cores specifically for these workloads suggests that the company’s internal benchmarking has identified a clear performance or efficiency advantage over general-purpose alternatives.
This is not a rejection of GPU infrastructure but an acknowledgment that the agentic layer of the AI stack has its own distinct compute profile. The CPU:GPU ratio is inverting drastically in agentic AI workloads, with Arm estimates suggesting it could shift from 3x-5x CPUs to GPUs at scale, as laid out in a recent Techstrong webinar. As agentic AI moves from experimental deployments to production-scale systems handling billions of interactions, the infrastructure mix powering these systems will increasingly diverge from training-focused clusters. Infrastructure planning for AI is becoming a multi-silicon discipline, and organizations that treat it as a single-accelerator problem risk misallocating capital.
Custom Silicon as a Cloud Differentiation Strategy
AWS’s Graviton line has evolved from a cost-optimization alternative to x86 instances into a strategic asset capable of anchoring hyperscale AI deployments. The Meta deal follows Anthropic’s reported commitment of up to $100 billion in AWS custom silicon, collectively demonstrating that purpose-built processors are no longer peripheral to AWS’s cloud value proposition but central to it. By controlling the full stack from chip design through server architecture via the Nitro System, AWS can deliver optimizations in latency, bandwidth, and energy efficiency that off-the-shelf processors cannot replicate at a comparable scale.
Graviton5’s 33% reduction in inter-core communication delays and support for the Elastic Fabric Adapter directly address the low-latency, high-bandwidth requirements of distributed agentic workloads. This vertical integration model gives AWS a structural advantage in competing for workloads where performance-per-watt and cost-per-inference matter as much as raw throughput. AWS testing results suggest efficiency improvements in ML workloads, including 35% gains on PyTorch, subject to independent testing. Meta’s development of the PyTorch framework makes these gains material for their high-value workolads. Custom silicon is becoming a decisive factor in which cloud provider wins the infrastructure layer of the agentic AI market.
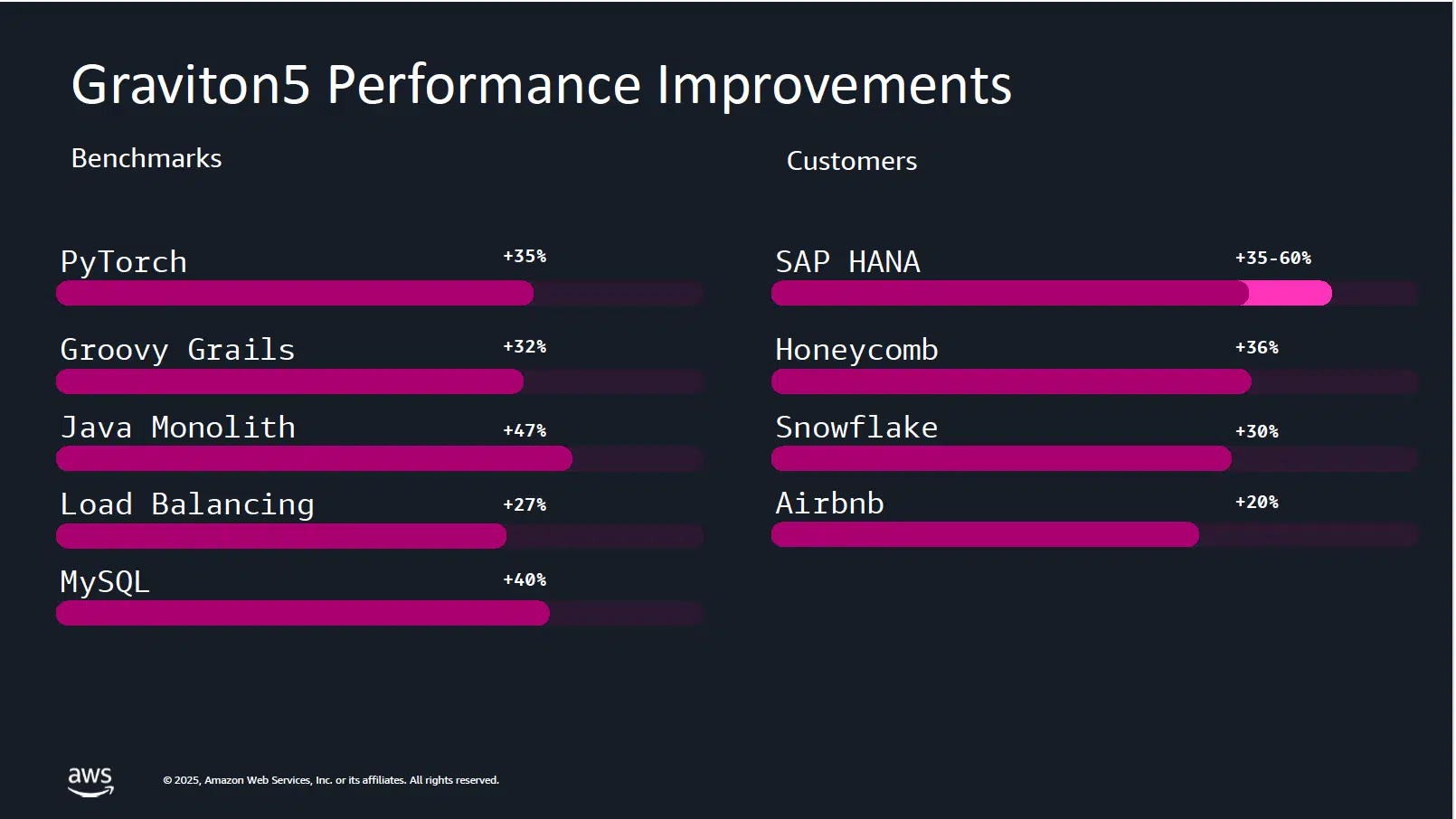
Compute Diversification as a Strategic Imperative
Meta’s framing of this deal as part of a broader compute diversification strategy is notable for its breadth and depth of engagement. The company has simultaneously invested heavily in AMD CPUs, NVIDIA GPUs, partnered with Broadcom on custom 2nm AI accelerators, co-designed CPUs with Arm, and is now committed to AWS Graviton at scale, signaling a deliberate multi-vendor, multi-architecture approach to AI infrastructure. This strategy mitigates supply chain concentration risk, provides workload-specific optimization options, and creates negotiating leverage across the semiconductor and cloud ecosystems.
For AWS, securing Meta as one of its largest Graviton customers validates the commercial viability of custom Arm-based CPUs against entrenched x86 incumbents from Intel and AMD in high-performance compute environments. Meta has been in the process of migrating x86 workloads to Arm, contributing to Arm achieving 50% market share in hyperscaler CPU server adoption, though it will use both for its variety of cloud tasks. The deal also suggests that Meta views cloud-based CPU capacity as complementary to, rather than competitive with, its own on-premises infrastructure buildout. The largest AI builders are converging on hybrid, multi-silicon strategies, and infrastructure providers that offer only one dimension of the compute stack will face increasing pressure.
Energy Efficiency as an Infrastructure Decision Factor
At the scale Meta operates, marginal improvements in performance-per-watt translate into material differences in operational cost and sustainability outcomes. Graviton5’s 3nm process and AWS’s end-to-end design control via Annapurna Labs enable efficiency gains that compound across tens of millions of cores, directly affecting both total cost of ownership and environmental footprint. Meta has publicly committed to sustainability targets, and selecting infrastructure that delivers stronger performance while maintaining leading energy efficiency aligns compute procurement with those corporate objectives.
As industry-wide AI compute demand accelerates, with Amazon alone planning $200 billion in capital expenditure in 2026, the efficiency of the underlying infrastructure becomes a competitive differentiator rather than a secondary consideration. Regulators and investors are increasingly scrutinizing the energy intensity of AI operations, adding external pressure to the internal economic case for efficient silicon. Energy efficiency is transitioning from a cost saving measure to a material factor in large-scale AI infrastructure procurement decisions.
What to Watch:
- Whether Graviton5 extends Graviton4’s lead in LLM performance in comparative tests
- How TSMC’s expansion of the 3nm node affects Graviton volumes
- How Meta’s Muse Spark foundation model improves with continuous reinforcement learning
- If AWS gains an advantage over other cloud providers due to its volume of Graviton processors
- How Meta balances its AWS Graviton commitments as part of its portfolio approach to personal superintelligence compute
See the full press release on Amazon Web Services’ Meta Graviton agreement announcement on the company website.
Disclosure: Futurum is a research and advisory firm that engages or has engaged in research, analysis, and advisory services with many technology companies, including those mentioned in this article. The author does not hold any equity positions with any company mentioned in this article.
Analysis and opinions expressed herein are specific to the analyst individually and data and other information that might have been provided for validation, not those of Futurum as a whole.
Other Insights from Futurum:
Is Anthropic’s $100 Billion Pact for AWS Silicon a Bargain in a Supply-Constrained Market?
Amazon Q4 FY 2025: Revenue Beat, AWS +24% Amid $200B Capex Plan
Will NVIDIA’s Meta Deal Ignite a CPU Supercycle?
Image Credit: AWS
Author Information

Brendan is Research Director, Semiconductors, Supply Chain, and Emerging Tech. He advises clients on strategic initiatives and leads the Futurum Semiconductors Practice. He is an experienced tech industry analyst who has guided tech leaders in identifying market opportunities spanning edge processors, generative AI applications, and hyperscale data centers.
Before joining Futurum, Brendan consulted with global AI leaders and served as a Senior Analyst in Emerging Technology Research at PitchBook. At PitchBook, he developed market intelligence tools for AI, highlighted by one of the industry’s most comprehensive AI semiconductor market landscapes encompassing both public and private companies. He has advised Fortune 100 tech giants, growth-stage innovators, global investors, and leading market research firms. Before PitchBook, he led research teams in tech investment banking and market research.
Brendan is based in Seattle, Washington. He has a Bachelor of Arts Degree from Amherst College.





