Analyst(s): Brendan Burke
Publication Date: April 10, 2026
SiFive has closed a $400 million oversubscribed Series G round to accelerate its high-performance RISC-V data center roadmap, backed by investors including Atreides Management, Apollo Global Management, NVIDIA, and T. Rowe Price. The funding underscores a broader industry shift in which hyperscalers are actively seeking customizable, open-standard CPU intellectual property to address the growing orchestration demands of agentic AI workloads.
What is Covered in This Article:
- SiFive’s $400 million Series G and data center acceleration plans
- The memory wall redefining AI compute architecture requirements
- Decoupled vector pipelines as a latency-hiding mechanism
- RISC-V as an open-standard counterweight to proprietary ISA lock-in
- Execution risk in bridging IP licensing and production-grade silicon
The News: SiFive announced on April 9, 2026, that it has raised $400 million in an oversubscribed Series G financing round, valuing the company at $3.65 billion. The round was led by Atreides Management, with participation from Apollo Global Management, NVIDIA, Point72 Turion, T. Rowe Price Investment Management, and returning investors Prosperity7 Ventures and Sutter Hill Ventures. The funding is earmarked for accelerating SiFive’s RISC-V CPU and AI intellectual property (IP) solutions for the data center, including advanced research and development in scalar, vector, and matrix compute, software ecosystem expansion, and customer enablement.
SiFive CEO Patrick Little stated that hyperscale customers have made it clear that “it is time to accelerate the availability of open standard alternatives for the data center,” citing demand for customizable CPU solutions in IP form that enable customers to differentiate their compute platforms. The company cited agentic AI workloads as a primary growth driver, positioning RISC-V as the architecture best suited to deliver the performance, power efficiency, and architectural flexibility that hyperscalers require. SiFive reported record growth in 2025, with its IP featured in more than 500 designs and over 10 billion cores shipped to date.
Will SiFive’s $400 Million Round Unblock the Data Center CPU Bottleneck?
Analyst Take: SiFive’s $400 million raise arrives at a moment when the primary bottleneck for AI compute is shifting from raw arithmetic throughput to data movement and memory bandwidth. Futurum Group research has documented a CPU resurgence driven by agentic reasoning workloads, with Reinforcement Learning with Verifiable Rewards (RLVR) and agentic workflows pushing CPU-to-GPU ratios in AI clusters back toward 1:1.
The memory wall — where transformer-based large language model (LLM) parameters and Key-Value (KV) caches routinely exceed GPU high-bandwidth memory capacities — has exposed fundamental inefficiencies in legacy instruction set architectures (ISAs) that were never designed for these access patterns. SiFive’s RISC-V data center CPU IP, built around a decoupled vector architecture and configurable latency-hiding queues, represents a direct architectural response to this bottleneck. The critical question is whether microarchitectural elegance at the IP level can translate into production-grade data center silicon before the window of supply constraint closes.
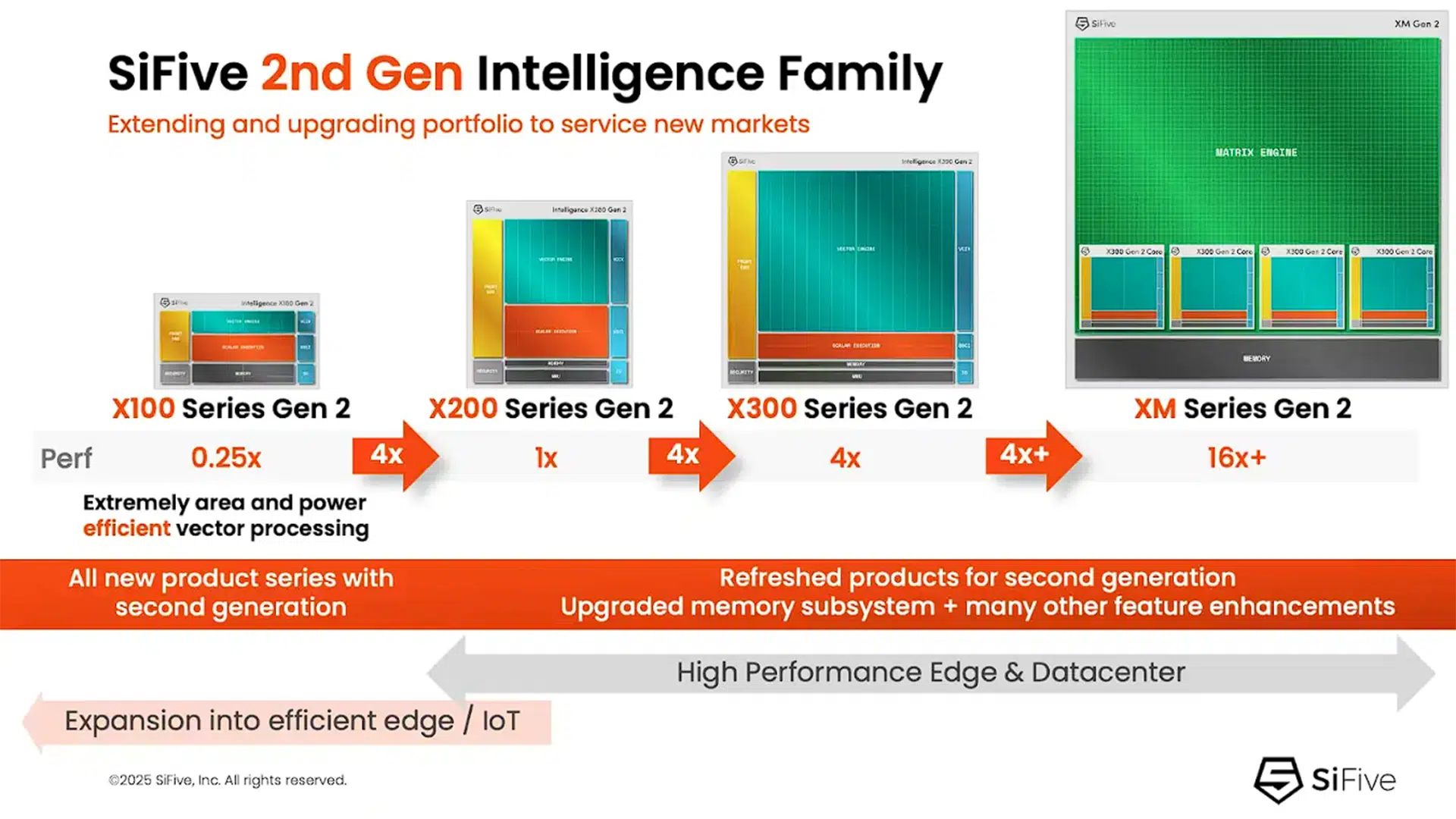
Figure 1: Indicative SiFive 2nd Generation Intelligence Family Processor Architecture

The Memory Wall Is Redefining What AI Compute Architectures Must Solve
The dominant narrative of GPU supremacy in AI has obscured a structural reality: during the decode phase of LLM inference, GPU FLOP utilization rates can fall to 10 percent or lower as processors wait for model weights to be loaded from off-chip memory. Mixture of Experts (MoE) models compound this problem by requiring that massive parameter sets reside in memory even though only a fraction are activated for any single input, creating a bandwidth bottleneck that raw compute power cannot resolve. Standard CPU and GPU architectures rely on complex hierarchies of caches managed by control logic, but the massive matrix traversals required by LLMs lead to severe cache thrashing where data blocks are evicted just before they are needed again.
SiFive’s approach addresses this at the microarchitectural level through selective cache bypassing, which directs vector loads to the L2 or a dedicated Core Local Port while the L1 cache remains dedicated to control flow data. This design yields a non-blocking weight-delivery system that maintains deterministic performance even as model sizes scale, a capability that legacy ISAs cannot retrofit without fundamental redesign. The implication is that the memory wall is not a temporary supply constraint but a permanent architectural challenge, and solutions must be embedded in the instruction set and pipeline design rather than bolted on through software workarounds.
Decoupled Vectors and Latency-Hiding Queues Offer a Distinct Engineering Path
SiFive’s 2nd Generation Intelligence family loosely decouples the scalar pipeline from the vector pipeline, allowing the scalar unit to race ahead and pre-fetch data while the vector engine focuses on heavy data processing. The configurable Vector Load Data Queue (VLDQ) acts as a high-speed staging area, enabling a perceived load-to-use latency of one cycle by ensuring that data has already returned from memory by the time the vector unit is ready to compute. In a four-core cluster configuration, the X390 processor can maintain 1,024 outstanding memory requests within a single-threaded model, achieving the latency-masking power of GPUs without the silicon tax of massive register files and complex context management logic.
Figure 2: Outstanding Memory Requests
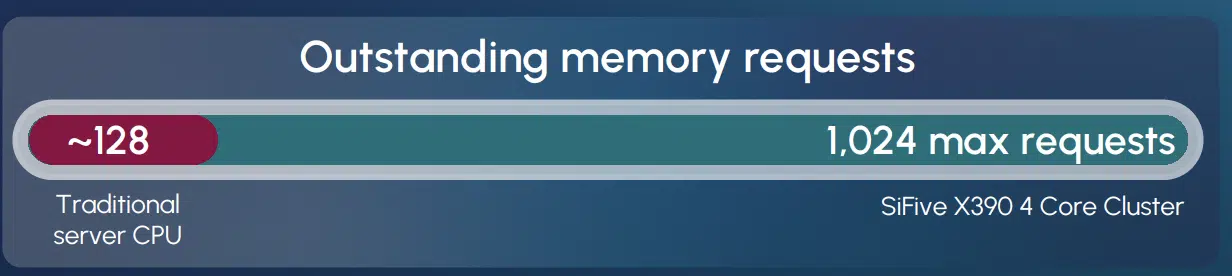
This single-threaded deterministic approach removes the jitter and latency penalties common in heavily multithreaded systems, a characteristic that aligns with the requirements of high-reliability agentic inference, where predictable throughput matters more than peak theoretical performance. The configurable depth of the VLDQ allows architects to size the queue for specific silicon topologies, from multi-chiplet designs where deep queues mask die-to-die interconnect latencies to low-latency memory configurations where the queue can be minimized to reduce silicon footprint. SiFive’s architectural innovations address the memory wall at the pipeline level rather than at the system level, offering a fundamentally different engineering path from the brute-force bandwidth scaling that has defined the GPU era.
RISC-V’s Open-Standard Position Strengthens as Proprietary Ecosystems Fracture
SiFive’s strategic thesis rests on a structural claim that proprietary ISAs have constrained how chip designers build and differentiate their silicon, and that hyperscalers are now actively seeking open-standard alternatives that offer architectural freedom without vendor dependency. This framing gains credibility from NVIDIA’s own trajectory: the company has shipped over a billion RISC-V cores to replace proprietary Falcon microcontrollers, announced intentions to port its CUDA stack to the RVA23 profile, and now participates as an investor in SiFive’s Series G. The recently ratified RVA23 profile provides a standard software foundation that bundles essential extensions into a mandatory feature set while allowing deep differentiation, and the alignment of Red Hat Enterprise Linux 10 and Ubuntu with this profile marks RISC-V’s transition from experimental architecture to a production-ready operating system foundation.
Google’s use of the SiFive Intelligence X280 with VCIX in its Tensor Processing Unit (TPU) further validates the architecture’s readiness for the most demanding AI workloads in production environments. Meanwhile, the broader RISC-V ecosystem has attracted significant corporate investment, with Meta acquiring Rivos and Qualcomm acquiring Ventana, signaling that the architecture’s commercial gravity has reached a tipping point. RISC-V is no longer competing on theoretical openness alone but on demonstrated production deployments, ecosystem maturity, and the fracturing economics of proprietary ISA licensing.
IP Licensing Momentum Must Now Survive the Data Center Execution Gap
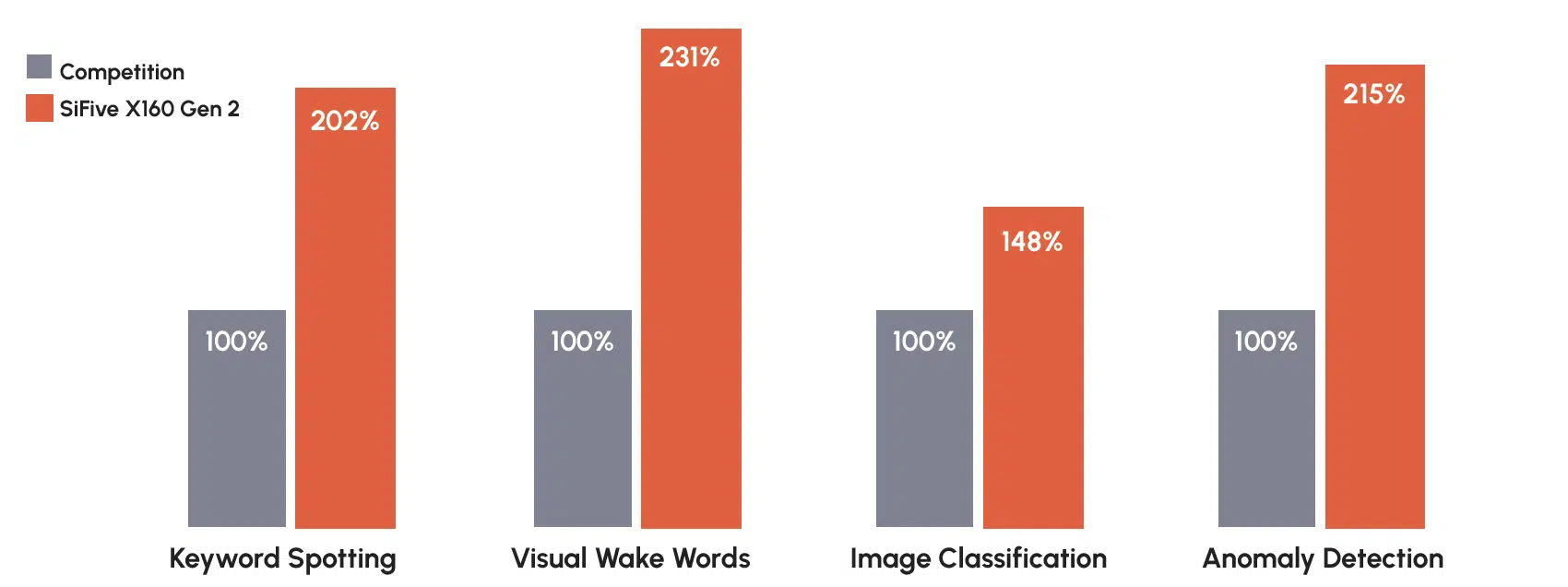
SiFive’s 10 billion shipped cores and 500-plus designs represent meaningful commercial validation, but the vast majority of this volume has been concentrated in embedded, edge, and accelerator control applications rather than standalone data center compute. The company’s edge AI performance — delivering up to two times the inference performance of CPU competitors for common edge tasks such as keyword spotting, visual wake words, and anomaly detection — demonstrates microarchitectural competence, yet data center server CPUs face a distinct set of validation requirements around single-threaded performance, enterprise software compatibility, and reliability at scale.
Figure 3: Normalized Inference Performance: SiFive vs. Competition
The software ecosystem, while rapidly maturing through IREE and LLVM compiler toolchains and the SiFive Kernel Library (SKL), still requires the kind of extensive validation and optimization that x86 and Arm have accumulated over decades of data center deployment. SiFive acknowledges that high-performance deployments still benefit from a human-in-the-loop approach for the most compute-intensive kernels, suggesting that the fully automated compiler path is not yet sufficient for production-critical workloads. The $400 million in new capital provides a runway for research, development, and customer enablement, but converting IP roadmaps into tape-outs, foundry validation, and volume production involves multi-year timelines that may not align with the urgency of agentic workload demand. SiFive’s funding closes the investment gap, but the execution gap between licensable IP and deployable data center silicon remains the company’s most consequential challenge.
What to Watch:
- Whether hyperscalers publicly commit to RISC-V-based data center CPU programs beyond accelerator control roles within the next 12 to 18 months.
- How quickly SiFive’s software ecosystem matures for data center workloads, particularly CUDA portability and enterprise Linux distribution validation on RVA23.
- The degree to which SiFive’s decoupled vector architecture and VLDQ translate from IP-level benchmarks to competitive silicon-level performance in foundry-produced chips.
- Whether NVIDIA’s CUDA-on-RISC-V initiative accelerates or constrains independent RISC-V software ecosystem development.
- The extent to which edge AI design wins, such as those powering NXP’s Kinara acquisition, creates a pipeline for data center customer engagement.
See the full press release on SiFive’s Series G funding announcement on the company website.
Disclosure: Futurum is a research and advisory firm that engages or has engaged in research, analysis, and advisory services with many technology companies, including those mentioned in this article. The author does not hold any equity positions with any company mentioned in this article.
Analysis and opinions expressed herein are specific to the analyst individually and data and other information that might have been provided for validation, not those of Futurum as a whole.
Other Insights from Futurum:
Arm’s $15 Billion CPU Opportunity Hinges on Agentic Data Center Design
Can the CPU Market Meet Agentic AI Demand?
SiFive and NVIDIA: Rewriting the Rules of AI Data Center Design
Image Credit: SiFive
Author Information

Brendan is Research Director, Semiconductors, Supply Chain, and Emerging Tech. He advises clients on strategic initiatives and leads the Futurum Semiconductors Practice. He is an experienced tech industry analyst who has guided tech leaders in identifying market opportunities spanning edge processors, generative AI applications, and hyperscale data centers.
Before joining Futurum, Brendan consulted with global AI leaders and served as a Senior Analyst in Emerging Technology Research at PitchBook. At PitchBook, he developed market intelligence tools for AI, highlighted by one of the industry’s most comprehensive AI semiconductor market landscapes encompassing both public and private companies. He has advised Fortune 100 tech giants, growth-stage innovators, global investors, and leading market research firms. Before PitchBook, he led research teams in tech investment banking and market research.
Brendan is based in Seattle, Washington. He has a Bachelor of Arts Degree from Amherst College.






