Analyst(s): Brad Shimmin
Publication Date: June 12, 2026
As artificial intelligence accelerates from generative assistance to autonomous execution, legacy data infrastructure faces a massive reckoning. Major database providers are actively rearchitecting their platforms to support the high-concurrency, strictly consistent, and multi-tiered memory requirements of autonomous agents. Here are the key takeaways as enterprises navigate this architectural transition.
Key Points:
- Autonomous AI agents require databases to evolve from passive storage into active systems capable of executing continuous decision-making loops.
- To prevent cascading errors, platforms must adopt unified multi-tiered memory, strong serializable consistency, and zero-copy speculative sandboxing.
- Database vendors are separating compute from storage to handle bursty AI traffic while embedding security rules natively to ensure agents act safely.
Overview:
The database industry is rapidly transitioning toward active, intelligent storage environments equipped with real-time change data capture, speculative execution sandboxes, and highly structured agentic memory capabilities.
As artificial intelligence is evolving rapidly to tackle autonomous execution, we are observing a clear progression in AI commerce from read-only chatbots to read-write autonomous agents capable of negotiating and executing complex transactions across enterprise environments without human intervention. Today, AI agents run always-on decision loops, drastically multiplying transaction volumes and requiring the ability to safely write execution states back to the system. And this evolution has exposed notable gaps in data infrastructure. Databases designed for predictable, human-centric queries are faltering under the always-on, high-velocity demands of autonomous fleets.
Figure 1: Top Infrastructure Bottlenecks for AI Agents
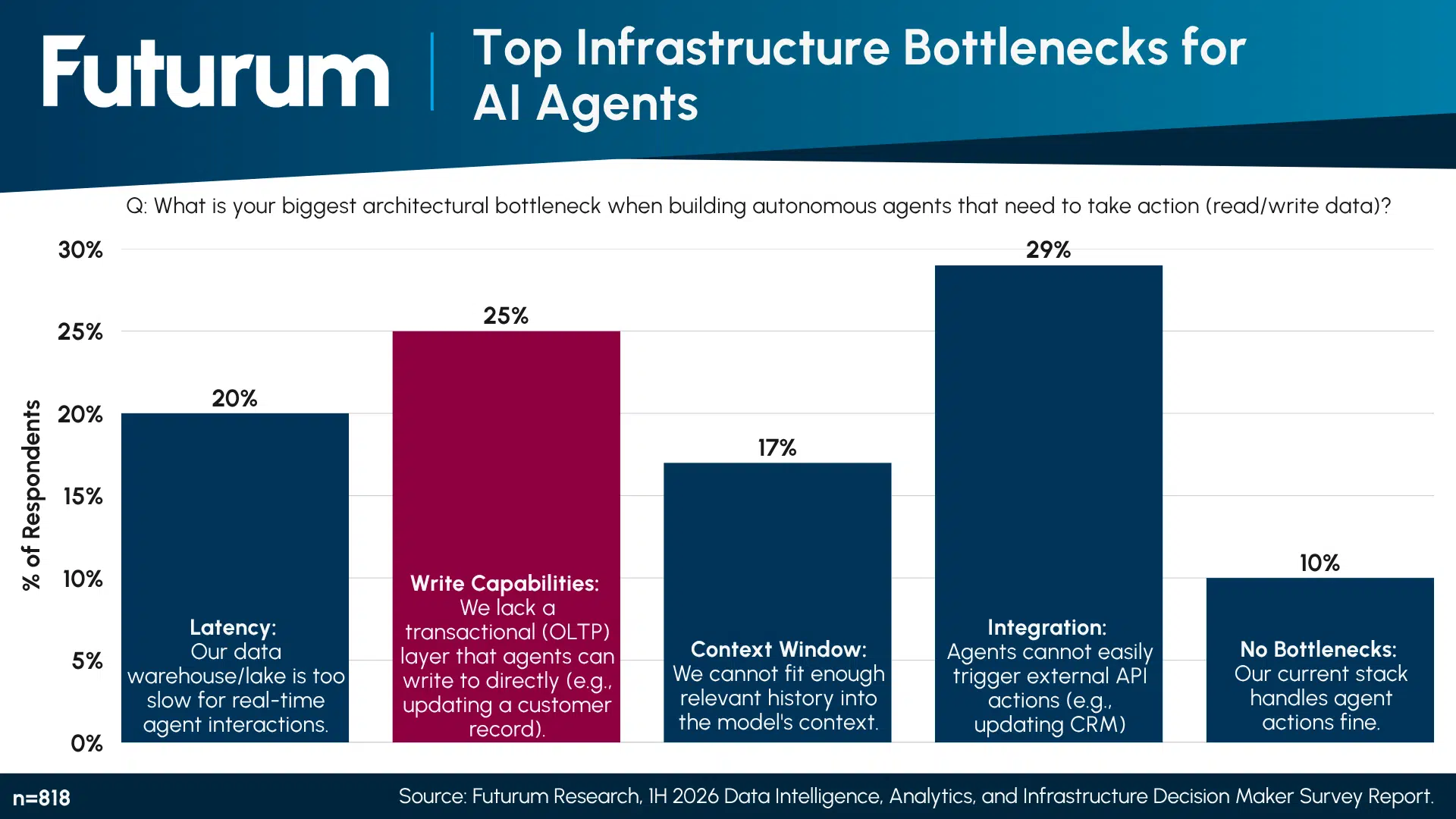
To support this new reality, data architectures are moving into two distinct groups: vertically integrated do-it-all databases capable of doing away with data movement; and a loosely composable disaggregated stack of best-of-need data processing and query engines. Both approaches attempt to answer similar questions, such as how to manage agentic memory at scale across distinct memory tiers (short-term workspaces, episodic logs, semantic knowledge, and procedural rules). The goal here is to deliver a unified, highly secure memory core that eliminates integration headaches and ensures agents have a single source of truth.
Another question these modern, agentic databases seek to answer involves speed and reliability. Can established norms such as eventual consistency hold up under the weight of unpredictable, autonomous operations? To answer that question, databases are adopting techniques such as serializable transaction isolation to prevent parallel agents from acting on stale data and causing cascading business errors. Similarly, to evaluate complex operational workflows safely, modern databases are utilizing decoupled architectures to provide agents with instant, zero-cost speculative sandboxes. This mathematical efficiency allows an AI to spin up a temporary copy of the database, test data mutations, and discard the sandbox without undue overhead or risking actual production data.
The vendor landscape is rapidly adapting to capture these workloads, with each vendor building on its own unique history and position within the market. Specialists are leaning into disaggregation, and generalists are pushing the performance boundaries of vertical integration. Platforms such as Oracle AI Database 26ai and Google Cloud AlloyDB, for example, are pulling compute inward, integrating SQL firewalls and native vector processing to secure agent logic natively. Conversely, solutions such as Databricks Lakebase and TiDB are exploiting decoupled, serverless architectures to instantly scale compute resources outward in response to volatile multi-agent traffic.
The trick for both providers and enterprise adopters lies in how these new agentic systems of action evolve to deliver not only capability but also observability, security, and governance. Futurum believes that databases cannot and should not delegate this important functionality to the application layer. By embedding these capabilities directly into the data architecture, enterprises can eliminate integration debt, protect sensitive assets, and build the highly reliable infrastructure necessary to power the next generation of autonomous operations. No matter the approach (consolidation or disaggregation), customer success will hinge upon how well the vendor community can unify agentic capabilities (transactional SQL, native vector processing, speculative sandboxing, agent memory, etc.) within a single, highly consistent agentic runtime.
The full report is available to read here and via subscription to Futurum Intelligence’s Data Intelligence, Analytics, & Infrastructure IQ service—click here for inquiry and access.
See the complete coverage on the evolution of AI infrastructure on the Futurum Intelligence Platform.
About the Futurum Data Intelligence, Analytics, & Infrastructure Practice
The Futurum Data Intelligence, Analytics, & Infrastructure Practice provides actionable, objective insights for market leaders and their teams so they can respond to emerging opportunities and innovate. Public access to our coverage can be seen here. Follow news and updates from the Futurum Practice on LinkedIn and X. Visit the Futurum Newsroom for more information and insights.
Futurum clients can read more about it in the Futurum Intelligence Platform, and non-clients can learn more here: Software Lifecycle Engineering Practice.
Author Information

Brad Shimmin is Vice President and Practice Lead, Data Intelligence, Analytics, & Infrastructure at Futurum. He provides strategic direction and market analysis to help organizations maximize their investments in data and analytics. Currently, Brad is focused on helping companies establish an AI-first data strategy.
With over 30 years of experience in enterprise IT and emerging technologies, Brad is a distinguished thought leader specializing in data, analytics, artificial intelligence, and enterprise software development. Consulting with Fortune 100 vendors, Brad specializes in industry thought leadership, worldwide market analysis, client development, and strategic advisory services.
Brad earned his Bachelor of Arts from Utah State University, where he graduated Magna Cum Laude. Brad lives in Longmeadow, MA, with his beautiful wife and far too many LEGO sets.