
Analyst(s): Brendan Burke
Publication Date: March 17, 2026
AWS and Cerebras have announced a multi-year collaboration that places Cerebras CS-3 wafer-scale engines alongside AWS Trainium chips inside AWS data centers, creating a disaggregated inference system accessible through Amazon Bedrock. The partnership represents a significant architectural departure from conventional GPU-centric inference, raising questions about how hyperscalers will compete on inference speed and efficiency as agentic and reasoning workloads intensify.
What is Covered in This Article:
- AWS-Cerebras collaboration for disaggregated cloud inference
- Prefill-decode separation as an architectural strategy
- Bedrock integration and enterprise accessibility implications
- Competitive positioning against GPU-centric inference approaches
- Shifting inference economics as agentic workloads scale
The News: AWS and Cerebras announced a multi-year collaboration to deploy Cerebras CS-3 wafer-scale engines within AWS data centers, marking the first time a major hyperscaler has hosted Cerebras hardware in its own infrastructure. The integrated system pairs AWS Trainium chips, optimized for prefill processing of input prompts, with Cerebras CS-3 hardware, optimized for decode or output token generation, connected via high-speed RDMA networking through AWS Elastic Fabric Adapter and managed under the AWS Nitro security perimeter. The solution will be delivered as a premium inference tier within Amazon Bedrock, requiring no new instance types or separate APIs from customers. AWS indicated the service will be available in the second half of the year, with deployment possible across its global data center footprint using standard rack configurations.
“Inference is where AI delivers real value to customers, but speed remains a critical bottleneck for demanding workloads like real-time coding assistance and interactive applications,” said David Brown, Vice President, Compute & ML Services, AWS. “What we’re building with Cerebras solves that: by splitting the inference workload across Trainium and the CS-3, and connecting them with Amazon’s Elastic Fabric Adapter, each system does what it’s best at. The result will be inference that’s an order of magnitude faster and higher performance than what’s available today.”
“Partnering with AWS to build a disaggregated inference solution will bring the fastest inference to a global customer base,” said Andrew Feldman, Founder and CEO of Cerebras Systems. “Every enterprise around the world will be able to benefit from blisteringly fast inference within their existing AWS environment.”
AWS Rises to the Agentic AI Moment With Cerebras Integration for Fast Inference
Analyst Take: The AWS-Cerebras collaboration is the strongest confirmation of our 2026 prediction that inference architecture will enter a phase of deliberate disaggregation, where workload-specific silicon replaces monolithic GPU deployments for latency-sensitive tasks. By splitting inference into prefill and decode stages and assigning each to purpose-built hardware, the partnership exploits a fundamental asymmetry: prefill is compute-intensive and parallelizable, while decode is sequential and memory-bandwidth-bound. Cerebras views coding agents as prefill-heavy, given the size of user prompts, making this partnership a wedge to grow in the fastest-growing AI use case.
This divide-and-conquer approach, surfaced through Bedrock as a managed service, positions AWS to offer a differentiated inference tier without requiring customers to manage heterogeneous hardware. Cerebras’ claimed 15x speed improvement in decode over conventional architectures, depending on model characteristics, could represent a material shift in inference price-performance if validated at scale.
The central question is whether this architectural model can sustain its advantages as model architectures evolve and competing hyperscalers respond with their own inference optimizations.
Disaggregated Inference Exploits Complementary Silicon Strengths
The core technical thesis of this collaboration rests on matching silicon characteristics to workload demands rather than forcing a single accelerator to handle both prefill and decode. Trainium3 UltraServer’s 144 GB HBM capacity and 2.5 PFLOPS of compute throughput make it well-suited for the parallel, memory-capacity-intensive prefill phase, while Cerebras’s 44 GB of on-chip SRAM delivers the 21 PB/s memory bandwidth needed for the sequential, bandwidth-bound decode phase. This pairing effectively gives the system the memory capacity of cluster-scale HBM for context processing and the speed of massively coherent SRAM for token generation, a combination that no single chip architecture can deliver today.
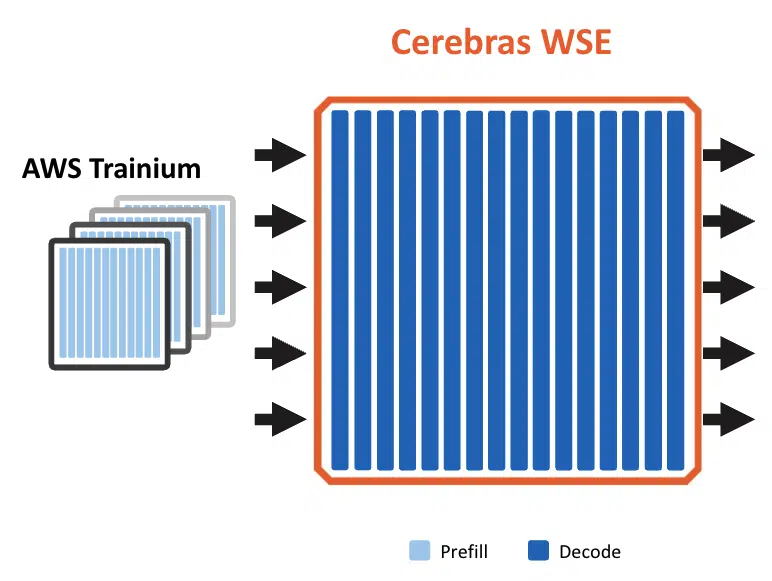
This deployment presents the long-awaited debut of Cerebras wafer-scale engines in hyperscale data centers. The approach addresses a historical limitation of Cerebras deployments, where keeping the wafer-scale engine continuously fed with off-chip data required substantial supporting memory systems. By offloading prefill entirely to Trainium Ultra servers, Cerebras can dedicate its full compute and memory resources to decode, eliminating the stranded capacity problem that constrained earlier standalone configurations. Our conversation with Cerebras suggests that its system can achieve 5x throughput by offloading prefill to Trainium, potentially yielding exponential gains in tokens per watt. The implication is that purpose-built silicon pairings may prove more efficient than general-purpose GPU scaling for inference workloads where latency is the primary optimization target.
Inference Speed Becomes a Competitive Moat as AI Moves from Novelty to Necessity
The timing of this announcement reflects a market shift in which inference latency has moved from a secondary consideration to a primary differentiator for AI service providers. As AI applications transition from experimental tools to daily productivity infrastructure, user tolerance for latency has collapsed, mirroring the pattern seen in web search and e-commerce delivery, where speed expectations ratcheted irreversibly upward. Anthropic’s ability to charge a 6x premium for 2x inference and still face capacity constraints provides direct market evidence that enterprises will pay substantially for faster output generation.
The AWS-Cerebras collaboration targets this willingness to pay with a solution that claims an order-of-magnitude improvement, positioning it as a premium tier within a service that already commands significant enterprise adoption. This dynamic is amplified by the growth of agentic workloads, where multi-step reasoning and code generation sessions produce decode-heavy token profiles that disproportionately benefit from faster output generation. The implication is that inference speed is transitioning from a technical benchmark to a commercial differentiator that shapes cloud provider market share and pricing power.
Hyperscaler Infrastructure Creates Durable Competitive Advantages
AWS is positioned to meet this Agentic AI moment because Trainium, Graviton CPU, and the Nitro networking chips were built as a coherent system. Trainium delivers high‑throughput, cost‑efficient prefill for large, complex prompts, while Graviton provides performant, energy‑efficient general compute for orchestration, token routing, caching, and control‑plane services that sit around the inference path. Underneath, the Nitro system and EFA networking supply the secure isolation, RDMA‑class bandwidth, and low latency needed to tie Trainium and Cerebras together as a single logical service within Bedrock. As cache offloading, model updates, and user behavior constantly reshape the prefill‑to‑decode ratio, AWS can dial up or down Trainium, Cerebras, and Graviton capacity across its global fleet, turning fast inference from a point solution into a durable, cloud‑scale capability.
What to Watch:
- Whether independent testing confirms the claimed 15x speed improvements across Amazon Nova
- How quickly major model providers such as Anthropic and OpenAI adopt the premium Bedrock inference tier, and what models will be supported
- Whether competing hyperscalers and chip companies respond with their own disaggregated inference architectures or accelerate custom silicon roadmaps to match the latency claims
- How the prefill-to-decode token ratio evolves as agentic, reasoning, and long-context workloads grow, and whether the Trainium-Cerebras pairing maintains its efficiency advantage
- The degree to which enterprise customers migrate from standard Bedrock inference to the premium tier provides a demand signal for latency-sensitive AI consumption
See the full press release on AWS’s Cerebras collaboration announcement on the Amazon website.
Disclosure: Futurum is a research and advisory firm that engages or has engaged in research, analysis, and advisory services with many technology companies, including those mentioned in this article. The author does not hold any equity positions with any company mentioned in this article.
Analysis and opinions expressed herein are specific to the analyst individually and data and other information that might have been provided for validation, not those of Futurum as a whole.
Other Insights from Futurum:
Amazon Q4 FY 2025: Revenue Beat, AWS +24% Amid $200B Capex Plan
SiFive and NVIDIA: Rewriting the Rules of AI Data Center Design
AWS European Sovereign Cloud Debuts with Independent EU Infrastructure
Author Information

Brendan is Research Director, Semiconductors, Supply Chain, and Emerging Tech. He advises clients on strategic initiatives and leads the Futurum Semiconductors Practice. He is an experienced tech industry analyst who has guided tech leaders in identifying market opportunities spanning edge processors, generative AI applications, and hyperscale data centers.
Before joining Futurum, Brendan consulted with global AI leaders and served as a Senior Analyst in Emerging Technology Research at PitchBook. At PitchBook, he developed market intelligence tools for AI, highlighted by one of the industry’s most comprehensive AI semiconductor market landscapes encompassing both public and private companies. He has advised Fortune 100 tech giants, growth-stage innovators, global investors, and leading market research firms. Before PitchBook, he led research teams in tech investment banking and market research.
Brendan is based in Seattle, Washington. He has a Bachelor of Arts Degree from Amherst College.





