
Analyst(s): Brendan Burke
Publication Date: March 4, 2026
Micron has begun sampling a 256GB SOCAMM2 module built on the industry’s first monolithic 32Gb LPDDR5X die, enabling 2TB of low-power memory per eight-channel server CPU. The announcement underscores a broader architectural transition in which CPU-attached LPDRAM is emerging as a critical memory tier for agentic AI workloads, with AMD and Qualcomm now exploring adoption alongside NVIDIA.
What is Covered in This Article:
- Micron’s 256GB SOCAMM2 launch and its implications for AI data center memory architecture
- The nonlinear relationship between near-compute memory capacity and inference performance
- AMD and Qualcomm are pursuing SOCAMM adoption, and what multi-vendor standardization signals
- How LPDRAM positions against RDIMMs and HBM in the evolving data center memory hierarchy
- The CPU market’s resurgence as agentic AI shifts investment toward inference-class compute
The News: Micron Technology on March 3 announced it has shipped customer samples of its 256GB SOCAMM2 module, the highest-capacity low-power double data rate random-access memory (LPDRAM) module produced for data center infrastructure. The module is enabled by the industry’s first monolithic 32Gb low-power double data rate 5X (LPDDR5X) die, manufactured on Micron’s 1-gamma (1γ) process node using extreme ultraviolet (EUV) lithography, which represents the company’s most advanced DRAM manufacturing technology. The 256GB module provides 33% more capacity than the prior highest-capacity 192GB SOCAMM2 and enables 2TB of LPDRAM per eight-channel server CPU.
Can Micron’s Modular Memory Upgrade Help NVIDIA’s CPUs Outperform?
Analyst Take: Micron’s 256GB SOCAMM2 announcement is significant not only for the capacity milestone itself, but also for what it reveals about the emerging architectural consensus in AI data center infrastructure. Micron co-designed SOCAMM2 memory with NVIDIA, most recently for the Vera Rubin AI platform. Vera CPUs were disclosed to carry 1.5 TB of SOCAMM LPDDR5X for improved serviceability and fault isolation. This capacity increase allows NVIDIA to upgrade LPDDR5X from 1.5TB on Vera Rubin to 2TB on Rubin Ultra or standalone Vera launches.
NVIDIA’s Vera CPUs complement GPU-level resiliency with in-system CPU core validation, enabling the rollout of standalone CPUs across Tier 1 customers such as CoreWeave and Meta. This announcement reflects that CPU-attached LPDRAM is transitioning from a bespoke NVIDIA co-design into an industry-wide memory tier with standardized JEDEC backing. For enterprise technology buyers, the Micron 256GB SOCAMM2 module may represent a more consequential shift than many next-generation GPU announcements, because the CPU market is more prone to disruption and more accessible than frontier GPU racks.
Near-Compute Memory and the Inference Bottleneck
In the field of tokenomics, memory capacity is proving to be a disproportionate value driver. Micron’s research shows that 33% more memory yields a 2.3x improvement in time to first token (TTFT) for 500k-token context lengths, suggesting a nonlinear relationship between near-compute memory capacity and inference throughput. This test was done on Llama-3 70B at FP16, and if this ratio holds under production conditions with frontier open-source models, it challenges the prevailing assumption that inference bottlenecks are primarily a function of accelerator compute or high-bandwidth memory (HBM) capacity. Instead, it positions the CPU memory subsystem as a first-order constraint on the long-context, agentic AI workloads that are increasingly defining enterprise deployment requirements.
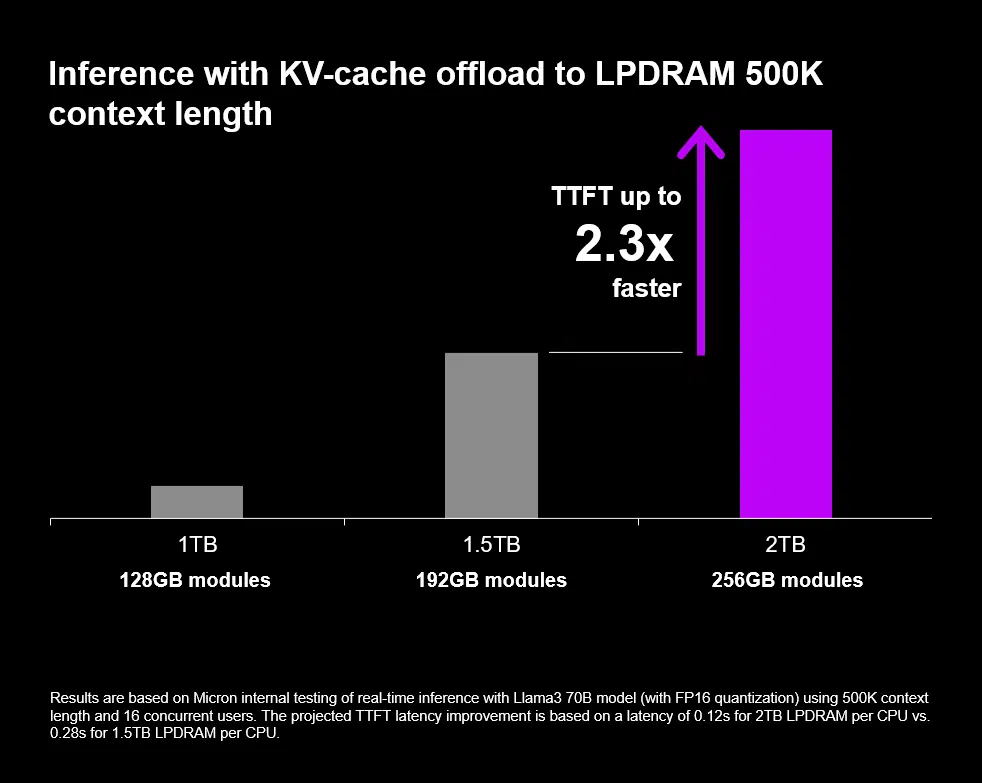
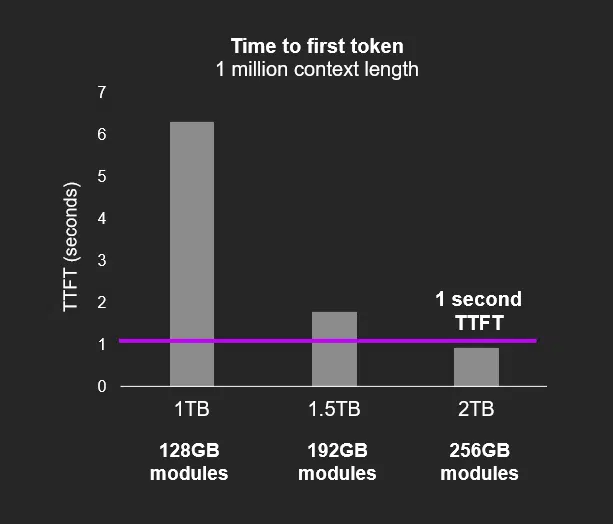
Agentic AI architectures require millions of tokens to be held active in working memory for persistent key-value (KV) caches and multi-turn reasoning. These workloads cannot rely solely on HBM, which remains expensive and capacity-limited. SOCAMM’s ability to deliver terabytes of memory per CPU at one-third the power of RDIMMs creates a complementary tier that addresses capacity-bound, latency-sensitive workloads that HBM alone cannot economically serve. A one-second TTFT at a one-million-token context length meets the responsiveness threshold that determines whether agentic AI applications are viable in production environments.
The Power Efficiency Equation Reshapes Total Cost of Ownership
The power efficiency dimension of this announcement may ultimately prove more important than the capacity headline. Doubling memory capacity within an identical power envelope — 256GB consuming the same wattage as 128GB did 12 months ago — represents a step-function improvement in performance per watt that directly affects data center total cost of ownership (TCO). In thermally constrained environments where power is the binding resource, this means system architects can add meaningful memory capacity without requiring additional cooling infrastructure or power delivery upgrades. This matters because data center power constraints are rapidly becoming the primary limiter of AI infrastructure scaling.
Multi-Vendor Adoption Signals a Structural Shift
When SOCAMM was an NVIDIA-exclusive co-design with Micron, it could be dismissed as a proprietary architectural choice. According to Hankyung, three major silicon vendors are now exploring the form factor, and SOCAMM is transitioning toward becoming an industry-standard memory tier. AMD and Qualcomm are reportedly pursuing a square module with on-module PMICs, unlike NVIDIA’s approach. This is not unusual for an emerging standard — it suggests that each vendor is optimizing SOCAMM for its own system architecture rather than simply copying NVIDIA’s implementation. The on-module power regulation approach that AMD and Qualcomm are exploring could reduce motherboard manufacturing complexity, lowering system-level costs and potentially accelerating adoption among original design manufacturers (ODMs) building AI rack infrastructure. The SOCAMM adoption trajectory could meaningfully shift CPU market share if ARM-based CPU architectures such as NVIDIA’s Grace and Qualcomm’s server processors gain disproportionate memory advantages through LPDRAM integration.
The Emerging Three-Tier Memory Architecture
What this announcement ultimately signals is the crystallization of a three-tier memory hierarchy for AI data centers: HBM for bandwidth-intensive GPU compute, LPDRAM via SOCAMM for capacity-dense CPU-attached inference and agentic workloads, and DDR5 RDIMMs for general-purpose compute that prioritizes backward compatibility over power efficiency. Each tier serves a distinct workload profile, and the system-level value emerges from how effectively platform architects orchestrate data movement across all three tiers. For infrastructure decision-makers, the actionable takeaway is that memory architecture planning for AI deployments should no longer be GPU-centric alone. The CPU memory subsystem is becoming a first-order design decision that directly influences inference latency, power consumption, and long-term TCO. Micron’s 256GB SOCAMM2 does not answer every question about how this transition will unfold, but it establishes the capacity and efficiency benchmarks that the rest of the industry will now be measured against.
What to Watch:
- The qualification timeline for Micron’s 256GB SOCAMM2 in NVIDIA’s Vera Rubin and Rubin Ultra platforms will determine whether the 2TB LPDDR5X configuration ships in volume production or remains a roadmap aspiration through late 2026.
- AMD and Qualcomm’s SOCAMM module designs, particularly the on-module PMIC approach, will require their own qualification cycles and ecosystem enablement before competing with NVIDIA’s established SOCAMM co-design relationship with Micron.
- Micron’s ability to scale 1-gamma EUV production to meet demand across both mobile LPDDR5X and data center SOCAMM2 will depend on expansion timelines at its Hiroshima fab, supported by the Japanese government, and access to EUV lithography.
- Enterprise buyers should track real-world benchmark data on SOCAMM2-equipped Vera CPUs under production agentic AI workloads, as the 2.3x TTFT improvement cited by Micron reflects controlled conditions that may not fully translate to heterogeneous deployment environments.
See the complete press release on the launch of 256GB SOCAMM2 module on the Micron website.
Disclosure: Futurum is a research and advisory firm that engages or has engaged in research, analysis, and advisory services with many technology companies, including those mentioned in this article. The author does not hold any equity positions with any company mentioned in this article.
Analysis and opinions expressed herein are specific to the analyst individually and data and other information that might have been provided for validation, not those of Futurum as a whole.
Other Insights from Futurum:
Can the CPU Market Meet Agentic AI Demand?
Micron Technology Q1 FY 2026 Sets Records; Strong Q2 Outlook
At CES, NVIDIA Rubin and AMD “Helios” Made Memory the Future of AI
Author Information

Brendan is Research Director, Semiconductors, Supply Chain, and Emerging Tech. He advises clients on strategic initiatives and leads the Futurum Semiconductors Practice. He is an experienced tech industry analyst who has guided tech leaders in identifying market opportunities spanning edge processors, generative AI applications, and hyperscale data centers.
Before joining Futurum, Brendan consulted with global AI leaders and served as a Senior Analyst in Emerging Technology Research at PitchBook. At PitchBook, he developed market intelligence tools for AI, highlighted by one of the industry’s most comprehensive AI semiconductor market landscapes encompassing both public and private companies. He has advised Fortune 100 tech giants, growth-stage innovators, global investors, and leading market research firms. Before PitchBook, he led research teams in tech investment banking and market research.
Brendan is based in Seattle, Washington. He has a Bachelor of Arts Degree from Amherst College.





