
Analyst(s): Brendan Burke
Publication Date: January 12, 2026
At CES 2026, NVIDIA CEO Jensen Huang unveiled NVIDIA’s next-generation Vera Rubin AI platform, and AMD CEO Lisa Su introduced AMD’s Helios rack-scale platform, both planning production for 2026.
What is Covered in this Article:
- NVIDIA and AMD prioritized memory capacity and bandwidth in their latest rack-scale GPU server reveals.
- NVIDIA’s Rubin platform innovates across six chip subsystems and an in-rack storage system for fast access to long context.
- AMD’s “Helios” rack-scale platform stands out for high-bandwidth memory co-packaging.
- Both systems emphasize memory availability and bandwidth, but we believe that NVIDIA’s combination of high-bandwidth memory and integrated SSD storage will be more flexible for reasoning inference.
- Other CES semiconductor announcements emphasized the availability of open networking and advanced foundry services for XPU alternatives.
The News: At CES, NVIDIA Rubin and AMD “Helios” made memory the future of AI. NVIDIA and AMD unveiled their next-generation rack-scale platforms for AI computing at CES 2026, demonstrating readiness for production in 2026. NVIDIA zoomed in on the development of six new chips within one supercomputer. AMD stepped back to frame the need for yotta-scale computing to reach 5 billion users with agentic AI. The reveals highlighted the need for continued innovation in subsystems beyond the GPU to alleviate memory and power bottlenecks.
At CES, NVIDIA Rubin and AMD “Helios” Made Memory the Future of AI
Analyst Take: Semiconductor Leaders Accelerating in Lockstep — CES turned into the Super Bowl of AI semiconductor announcements, bridging the gap between high-performance computing and consumer applications. Both NVIDIA Rubin and AMD “Helios” demonstrated that AI leaders have planned ahead for physical bottlenecks, such as energy and memory, as well as supply chain constraints, with designs that future-proof their business models. The scale of GPU server rack announcements underscores that the future of digital experiences will stem from foundational breakthroughs in trillion-parameter models achieved through the co-design of hardware with frontier AI model techniques.
Through the co-design of their new racks with customer requirements, NVIDIA and AMD showed why they lead the XPU pack for AI acceleration. According to our Global Enterprise Decision Maker Survey, NVIDIA and AMD remain ahead of Google TPU, AWS Trainium, and Intel Gaudi for customer mindshare. Among customers that do mostly inference workloads, AMD performs even better at nearly 50% usage. This customer loyalty implies outstanding price-performance and robust software ecosystems.
Figure 1: Accelerator Vendor Usage
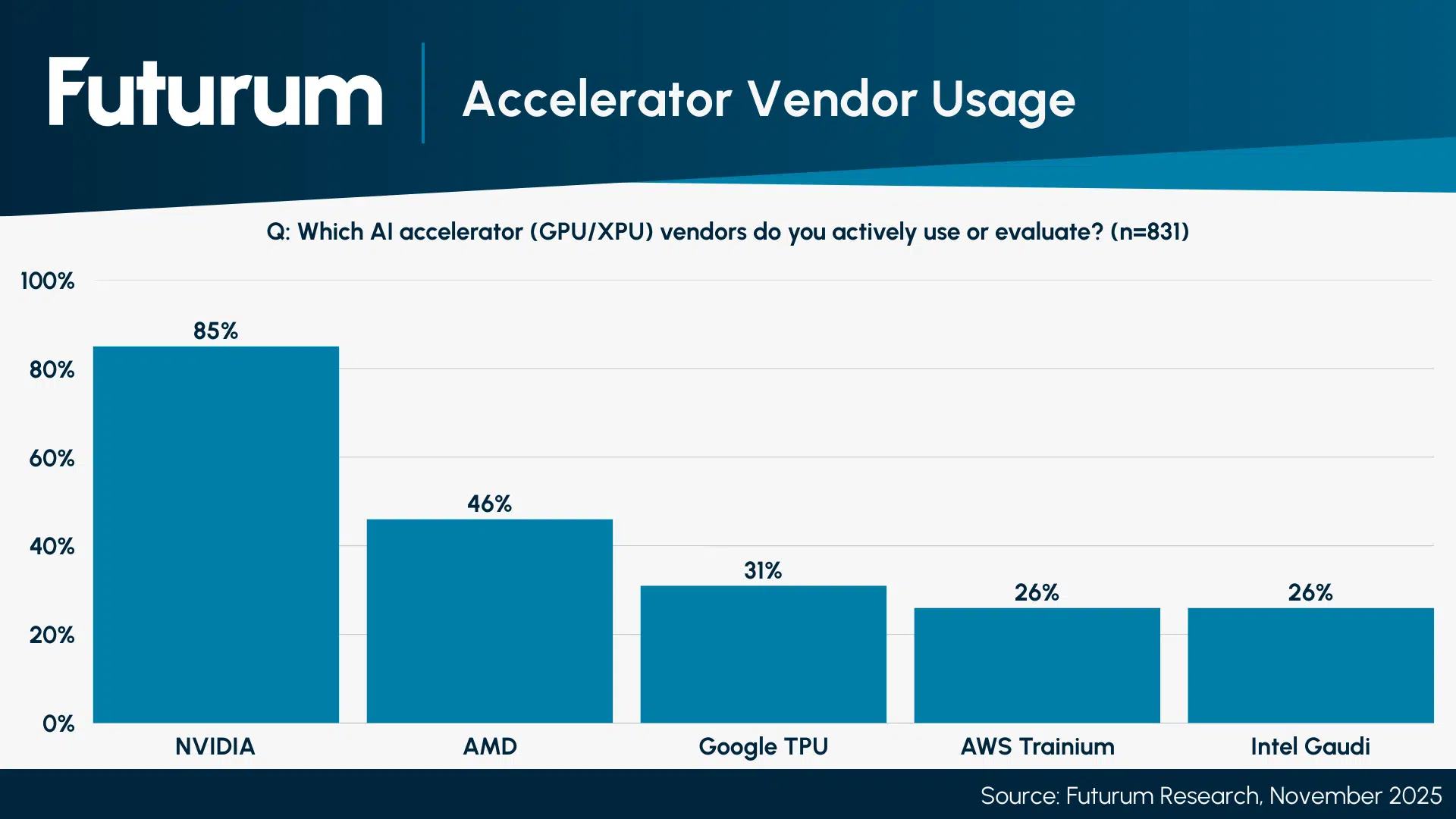
Source: Futurum Research, November 2025
The scale of these roll-outs will be determined by fabrication capacity and customer financing, not the quality of the architecture. Due to foundry bottlenecks, TSMC is accelerating capital expenditure plans ahead of 2027 for advanced node fabrication and CoWoS packaging, yet capacity for 2026 is all but fixed. NVIDIA will be TSMC’s leading customer in 2026, surpassing Apple by contributing around 20% of TSMC’s revenue. AMD will contribute less than half of this total across a wider product portfolio. Available wafers present an upper bound to unit shipments and AI scaling efforts, increasing the value of these systems to frontier AI customers.
NVIDIA Unveils Rubin
The leader in AI computing, NVIDIA, chose CES for the unveiling of its next-generation Vera Rubin platform. We believe that showcasing the system ahead of GTC, NVIDIA’s own conference, signals supply chain dominance and customer confidence to adopt the new GPU by year-end. Rubin stands out for its breathtaking scale and breakthrough memory utilization. To achieve performance improvements over the prior Blackwell generation of 5x for inference and 3.5x for training, with up to 3.6 exaflops of NVFP4 compute, Rubin synchronizes innovations across six subsystem chips while adding a new storage module called Inference Context Memory Storage based on the Bluefield data processing unit.

NVIDIA’s Inference Context Memory Storage drives continued innovation in storage that AI engineers need to handle massive context from long-running agentic sessions. To avoid starving GPUs of data, these custom SSD storage systems within each DGX SuperPOD cluster provide each GPU tray with 16x as much storage – 17 TB all-in. In highly interactive, agentic workloads, this architecture delivers up to 10x higher effective token generation per GPU compared to a baseline Blackwell system that relies on shared or remote storage, enabling customers to deploy large-scale agentic products with low latency and high user interactivity. Each GPU can access stored knowledge about each user at high data rates, encouraging NVIDIA customers to launch agentic products at scale. We believe long-context reasoning for both training and inference will be a driver of adoption for this system.
To facilitate high-speed data transfer, Bluefield-4 DPU improves tokens-per-second 5x over its prior generation with 5x greater power efficiency, impacting the critical tokens-per-watt metric. This capability compounds the 2.5x increase in HBM bandwidth for Rubin GPUs and the 3x increase in CPU system memory for Vera CPUs. Both Bluefield DPU and Vera CPU SoCs are built with Arm technology, showing the ecosystem needed to drive improved performance on dataflow tasks.
AMD Unveils Helios
AMD maintained its position as a viable complement to NVIDIA for frontier AI computing, announcing the Helios platform built around the Instinct MI400 series of GPUs, along with new designs for its data center CPU, NIC, and DPU. The Helios rack reaches 2.9 exaflops of FP4 compute and stands out for the scale of high-bandwidth memory available to each GPU, expanding the key-value caches available to the GPU with low latency. This architecture was endorsed by OpenAI’s President Greg Brockman for support of long-running agentic workflows, signaling a competitive architecture that will outperform NVIDIA for some tightly coupled tasks requiring a high volume of cutting-edge HBM4 memory.

XPUs and Robotics Chips Expand the Horizon
Semiconductor challengers showed that these platforms will not be the only drivers of AI scaling.
- Intel’s launch of Core Ultra Series 3, also known as Panther Lake, showed that its 18A process is up and running. This is the first consumer platform manufactured in Intel’s Arizona-based Fab 52 using 18A. 18A is the first node to successfully integrate RibbonFET Gate-All-Around and PowerVia Backside Power Delivery at scale, proving the transistor structure for its 14A process as well. This proof point will encourage XPU customers to use 14A for custom ASICs.
- Data center leader Marvell Technology announced the acquisition of XConn Technology, a scale-up networking startup focused on PCIe and CXL technology that can help with Marvell’s leadership in UALink networking. A fireside chat hosted by JP Morgan with Marvell’s CEO indicated that the company’s XPU opportunity will reaccelerate in 2027 across 15 production sockets, supported by recent customer commitments and interest in co-packaged optics.
- Robotics will be a major form factor for AI computing as evidenced by Arm’s announcement of a Physical AI unit for robotics-focused chip design, Boston Dynamics’ embrace of Google’s Gemini models in its new Atlas humanoid robot, and Qualcomm’s launch of the IQ10 robotics platform.
Taken together, these breakthroughs show that Semiconductor leaders can overcome supply chain constraints to deliver on scaling laws and edge inference.
What to Watch:
- Competitor announcements: The aggression of these moves pushes up the timeline for competition in chip architecture and customer commitments. Google Cloud Next in April is a likely venue to hear about the next generation of TPUs. NVIDIA will have the opportunity for additional silicon announcements at its GTC conference in March.
- Physical capacity is a differentiator: New data center capacity will dictate which can take advantage of the prodigious footprint of these GPU racks. Data centers coming online this year will be prepared to accept shipments and drive significant gains in token-per-watt performance.
- Customer shipment dates: Helios has been guided for shipment in Q3 2026, with Rubin following in Q4. Physical shipments of these systems will provide insight into how they perform in customer environments and the timing of potential 10 trillion-parameter frontier models.
See the complete press releases on NVIDIA Rubin on the NVIDIA website and AMD Helios on the AMD website.
Disclosure: Futurum is a research and advisory firm that engages or has engaged in research, analysis, and advisory services with many technology companies, including those mentioned in this article. The author does not hold any equity positions with any company mentioned in this article.
Analysis and opinions expressed herein are specific to the analyst individually and data and other information that might have been provided for validation, not those of Futurum as a whole.
Other insights from Futurum:
NVIDIA Q3 FY 2026: Record Data Center Revenue, Higher Q4 Guide
AMD Q3 FY 2025 Earnings Highlight Broad-Based Compute Momentum
Image Source: Generated by Gemini
Author Information

Brendan is Research Director, Semiconductors, Supply Chain, and Emerging Tech. He advises clients on strategic initiatives and leads the Futurum Semiconductors Practice. He is an experienced tech industry analyst who has guided tech leaders in identifying market opportunities spanning edge processors, generative AI applications, and hyperscale data centers.
Before joining Futurum, Brendan consulted with global AI leaders and served as a Senior Analyst in Emerging Technology Research at PitchBook. At PitchBook, he developed market intelligence tools for AI, highlighted by one of the industry’s most comprehensive AI semiconductor market landscapes encompassing both public and private companies. He has advised Fortune 100 tech giants, growth-stage innovators, global investors, and leading market research firms. Before PitchBook, he led research teams in tech investment banking and market research.
Brendan is based in Seattle, Washington. He has a Bachelor of Arts Degree from Amherst College.





