
Analyst(s): Brendan Burke
Publication Date: March 23, 2026
At OFC 2026, Marvell announced two 260-lane switches: one PCIe 6.0 and one CXL 3.0, both derived from its recently completed acquisition of XConn Technologies, creating the broadest open fabric-switching portfolio in the AI data center market. The dual launch aligns Marvell with the emerging UALink ecosystem and the broader industry effort to offer hyperscalers and XPU designers a credible, open alternative to NVIDIA’s NVLink at a moment when scale-up interconnect choices are becoming a strategic decision point.
What is Covered in This Article:
- Marvell’s simultaneous PCIe 6.0 and CXL 3.0 switch launches from the XConn acquisition
- How both products map to the UALink trajectory for XPUs
- The competition between UALink and NVLink
- Hyperscaler deployment as the gating factor for UALink market viability
- Memory wall and KV cache pressures driving composable infrastructure demand
The News: At OFC 2026 on March 17, 2026, Marvell Technology announced two new switching products, both built on intellectual property acquired through its recently completed acquisition of XConn Technologies. The Structera S 60260 is the industry’s first 260-lane PCIe 6.0 switch, and the Structera S 30260 is a 260-lane CXL 3.0 switch. Together, they represent the first time a single vendor has delivered both PCIe and CXL scale-up switching at this lane density from a unified technology base. The PCIe 6.0 switch addresses the growing challenge of connecting an increasing number of GPUs, XPU, and custom AI accelerators within a single server or rack. At 260 lanes, the Structera S 60260 offers roughly twice the lane density of competing offerings, eliminating the need for costly multi-device cascading.
Rishi Chugh, vice president and general manager of Marvell’s Data Center Switch Business Unit, noted that “Breaking through the AI memory wall requires a fundamental architectural change. The Structera SCXL switch is the first true CXL switching solution purpose-built for AI. By enabling composable memory across the fabric, we are fundamentally reshaping and improving memory pooling efficiency as AI infrastructure scales.”
Gerry Fan, senior vice president of engineering for scale-up switching at Marvell, emphasized that PCIe switching has evolved from supporting traditional CPU architectures to becoming an “essential building block for accelerated data center infrastructure,” optimized for low latency and power efficiency in AI and machine learning training workloads. Marvell describes this as the industry’s most comprehensive PCIe and CXL portfolio, covering the full signal path from accelerator to disaggregated memory.
Marvell’s XConn Buy Yields a Two-Pronged Open Fabric Play Against NVLink
Analyst Take — The XConn Acquisition as a Dual-Protocol Portfolio Accelerant: The strategic logic of Marvell’s XConn acquisition is now fully visiblewith two products addressing a distinct but interlocking bottleneck in AI data center architecture. On the PCIe side, the Structera S 60260 gives Marvell a density advantage that eliminates multi-device cascading at the exact moment when GPU and XPU counts per server are climbing rapidly. On the CXL side, the Structera S 30260 attacks the memory wall that is constraining inference workloads, particularly as KV cache sizes grow with longer context windows and multi-turn agentic workflows. The product can improve inference throughput by 4.8x and reduce time-to-first-token by 82.7% by pooling 16 TB of off-chip memory for an eight-GPU server, according to a Marvell blog post. The fact that both products emerged from a single acquisition and share a common 260-lane architecture underscores the efficiency of Marvell’s build-versus-buy calculus.
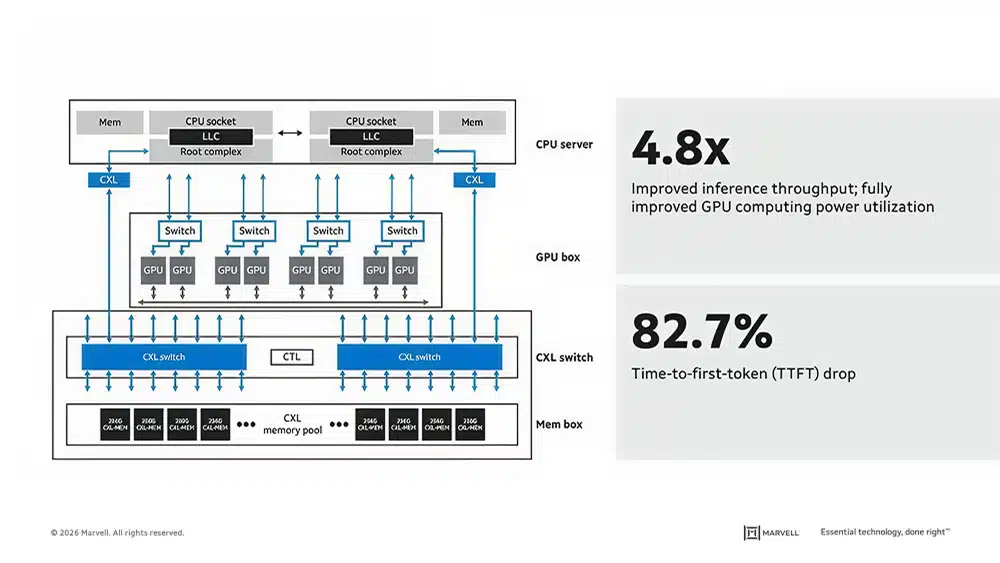
Rather than developing two separate silicon programs, Marvell acquired a switching IP base that could be instantiated across both protocols. These joint launches form an infrastructure layer that sits beneath whatever accelerator silicon a hyperscaler or enterprise operator chooses to deploy.
Alignment With the UALink Trajectory
The timing of these launches accelerates the broader industry tailwind toward Ultra Accelerator Link (UALink) as an open standard for scale-up interconnects. UALink is being developed as a PCIe- and CXL-derived fabric specifically designed to connect accelerators within a pod, and Marvell’s new switches are precisely the class of silicon that a UALink-based system would require. We believe that Ethernet- and PCIe-based variants of scale-up fabrics have a credible chance to challenge the historical dominance of NVLink, provided that contenders focus on minimizing power consumption, maximizing bandwidth, and potentially incorporating AI-specific network collectives.
The Structera S products check at least the first two of those boxes, with their density-driven power efficiency and aggregate bandwidth of up to 4 TB/s on the CXL variant. More importantly, the custom silicon ecosystem is actively pursuing UALink and PCIe/XGMI-based solutions as the foundation for open scale-up connectivity. Marvell’s dual-protocol switching portfolio makes it a natural infrastructure partner for this coalition.
The NVLink Parallel and the Cost-Flexibility Tradeoff
With these announcements, the NVLink-versus-open dynamic is increasingly resembling the earlier InfiniBand/Ethernet contest. In that historical precedent, InfiniBand was widely acknowledged as superior in performance, but Ethernet ultimately captured the broader market through advantages in availability, flexibility, and cost. With these open solutions, NVLink can retain its performance crown, as open alternatives gain share through lower switch costs, broader vendor support, and architectural flexibility. UALink’s proponents point to a scaling roadmap that extends to 1,024 nodes, beneficial latency characteristics for high-performance, agentic use cases and service management workloads, and switch costs expected to be lower than those of Ethernet-based alternatives.
The open-ecosystem argument is also significant: Ethernet-based scale-up options risk being largely controlled by Broadcom, whereas UALink is positioned as a genuinely multi-vendor standard. For Marvell, this framing is advantageous. Its Structera S switches are not competing head-to-head with NVLink on raw performance but rather offering the enabling silicon for an open ecosystem that competes on total cost of ownership, design freedom, and vendor diversity.
The Hyperscaler Gating Function
The critical caveat to this entire open fabric thesis is adoption. UALink still needs to be broadly deployed across a hyperscale cloud to become an actual market. Without a hyperscaler anchor tenant, UALink and its associated PCIe and CXL switching products remain a technically compelling but commercially unproven alternative. Marvell’s portfolio breadth, spanning switches, retimers, accelerators, and controllers, positions it well to be a primary supplier if and when that deployment materializes, but the company cannot will the ecosystem into existence on its own. The question for enterprise buyers and investors is not whether Marvell’s silicon is capable but whether the hyperscaler procurement cycle will validate the open fabric model at sufficient scale to create a self-sustaining ecosystem. Until that inflection point arrives, Marvell’s Structera S family represents a well-placed strategic bet rather than a confirmed revenue trajectory.
What to Watch:
- Reference design slot wins for the 260-lane PCIe 6.0 and CXL 3.0 switches with at least one major XPU vendor, including a hyperscaler custom silicon team, to convert the XConn acquisition’s technical assets into production-scale revenue.
- The UALink consortium is securing committed deployments to validate the open-fabric standard as a commercially viable alternative to NVIDIA’s NVLink
- CXL 3.0 memory pooling’s ability to deliver sub-microsecond latency under real-world KV cache workloads at rack scale, as data center operators will require production-grade validation before committing to disaggregated memory architectures over conventional HBM stacking
- Open fabrics closing the power efficiency and bandwidth gaps relative to NVLink while potentially incorporating AI-specific network collectives
- The broader success of PCIe- and CXL-based open fabrics in reshaping the scale-up interconnect market, creating a multi-vendor AI infrastructure ecosystem that mirrors the InfiniBand-to-Ethernet diversification pattern.
See the complete press release on the Marvell Structera S PCIe 6.0 switch for AI data center scale-up infrastructure on the Marvell website. See also the complete press release on the Marvell Structera S CXL switch enabling memory pooling on the Marvell website.
Disclosure: Futurum is a research and advisory firm that engages or has engaged in research, analysis, and advisory services with many technology companies, including those mentioned in this article. The author does not hold any equity positions with any company mentioned in this article.
Analysis and opinions expressed herein are specific to the analyst individually and data and other information that might have been provided for validation, not those of Futurum as a whole.
Other Insights from Futurum:
Broadcom’s DSP Launch Intensifies the AI Optics Race with Marvell
Marvell Technology Q4 FY 2026 Earnings Raise Data Center Growth Outlook
At CES, NVIDIA Rubin and AMD “Helios” Made Memory the Future of AI
Author Information

Brendan is Research Director, Semiconductors, Supply Chain, and Emerging Tech. He advises clients on strategic initiatives and leads the Futurum Semiconductors Practice. He is an experienced tech industry analyst who has guided tech leaders in identifying market opportunities spanning edge processors, generative AI applications, and hyperscale data centers.
Before joining Futurum, Brendan consulted with global AI leaders and served as a Senior Analyst in Emerging Technology Research at PitchBook. At PitchBook, he developed market intelligence tools for AI, highlighted by one of the industry’s most comprehensive AI semiconductor market landscapes encompassing both public and private companies. He has advised Fortune 100 tech giants, growth-stage innovators, global investors, and leading market research firms. Before PitchBook, he led research teams in tech investment banking and market research.
Brendan is based in Seattle, Washington. He has a Bachelor of Arts Degree from Amherst College.






